本教程假定你第一次,且没有搭建现有的Kafka或ZooKeeper。但是,如果你已经启动了Kafka和ZooKeeper,请跳过前两个步骤。
Kafka Streams结合了在客户端编写和部署标准Java和Scala应用程序的简单性以及Kafka服务器端集群技术的优势,使这些应用程序具有高度可伸缩性,弹性,容错性,分布式等特性。
这个快速入门示例将演示如何运行一个流应用程序。一个WordCountDemo的例子(为了方便阅读,使用的是java8 lambda表达式)
// Serializers/deserializers (serde) for String and Long types
final Serde<String> stringSerde = Serdes.String();
final Serde<Long> longSerde = Serdes.Long();
// Construct a `KStream` from the input topic "streams-plaintext-input", where message values
// represent lines of text (for the sake of this example, we ignore whatever may be stored
// in the message keys).
KStream<String, String> textLines = builder.stream("streams-plaintext-input",
Consumed.with(stringSerde, stringSerde);
KTable<String, Long> wordCounts = textLines
// Split each text line, by whitespace, into words.
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
// Group the text words as message keys
.groupBy((key, value) -> value)
// Count the occurrences of each word (message key).
.count()
// Store the running counts as a changelog stream to the output topic.
wordCounts.toStream().to("streams-wordcount-output", Produced.with(Serdes.String(), Serdes.Long()));
从输入的文本计算出一个词出现的次数。但是,不像其他的WordCount的例子,你可能会看到,在有限的数据基础上,执行的演示应用程序的行为略有不同,因为它应该是在一个无限数据的操作,数据流。类似的有界变量,它是一种动态算法,跟踪和更新的单词计数。然而,由于它必须假设潜在的无界输入数据,它会定期输出其当前状态和结果,同时继续处理更多的数据,因为它不知道什么时候它处理过的“所有”的输入数据。
作为第一步,我们将启动Kafka,然后我们将输入数据准备到Kafka主题,然后由Kafka Streams应用程序处理。
Step 1: 下载代码
下载kafka并解压它。注意,有多个可下载的Scala版本,我们选择在这里使用推荐版本(2.11):
> tar -xzf kafka_2.13-2.8.0.tgz
> cd kafka_2.13-2.8.0
Step 2: 启动kafka服务
Kafka使用Zookeeper,所以第一步启动Zookeeper服务。
> bin/zookeeper-server-start.sh config/zookeeper.properties
[2013-04-22 15:01:37,495] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)
...
现在启动 Kafka server:
> bin/kafka-server-start.sh config/server.properties
[2013-04-22 15:01:47,028] INFO Verifying properties (kafka.utils.VerifiableProperties)
[2013-04-22 15:01:47,051] INFO Property socket.send.buffer.bytes is overridden to 1048576 (kafka.utils.VerifiableProperties)
...
Step 3: 准备输入topic并启动Kafka生产者
接下来,我们创建一个输入主题“streams-plaintext-input”,和一个输出主题"streams-wordcount-output":
> bin/kafka-topics.sh --create \
--zookeeper localhost:2181 \
--replication-factor 1 \
--partitions 1 \
--topic streams-plaintext-input
Created topic "streams-plaintext-input".
注意:因为输出主题是更新日志流(参见下面的应用程序输出的说明),所以我们为输出主题启用了压缩。
> bin/kafka-topics.sh --create \
--zookeeper localhost:2181 \
--replication-factor 1 \
--partitions 1 \
--topic streams-wordcount-output \
--config cleanup.policy=compact
Created topic "streams-wordcount-output".
也可以使用kafka topic工具查看主题描述:
> bin/kafka-topics.sh --zookeeper localhost:2181 --describe
Topic:streams-plaintext-input PartitionCount:1 ReplicationFactor:1 Configs:
Topic: streams-plaintext-input Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:streams-wordcount-output PartitionCount:1 ReplicationFactor:1 Configs:
Topic: streams-wordcount-output Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Step 4: 启动 Wordcount 程序
以下命令启动WordCount演示程序:
> bin/kafka-run-class.sh org.apache.kafka.streams.examples.wordcount.WordCountDemo
演示程序将从输入主题streams-plaintext-input中读取,对每个读取消息执行WordCount算法计算,并将其当前结果连续写入输出主题streams-wordcount-output。 因此,除了日志条目外,不会有任何STDOUT输出,因为结果会写回到Kafka中。
现在我们另外开一个终端,来启动生产者来为该主题写入一些输入数据:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic streams-plaintext-input
在开一个终端,读取输出主题的数据。
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
Step 5: 处理数据
现在,我们通过输入一行文本然后按streams-plaintext-input。其中消息key为空,消息value为刚刚输入的字符串编码文本行(实际上,应用程序的输入数据通常会连续流入Kafka,而不是 像我们在这个快速入门中那样手动输入):
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic streams-plaintext-input
all streams lead to kafka
这些消息将被Wordcount程序处理,然后输出数据到streams-wordcount-output主题中,我们新打开一个命令窗口,输出消费者:
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
all 1
streams 1
lead 1
to 1
kafka 1
这里,第一列是java.lang.String格式的Kafka消息key,表示正在计数的单词,第二列是java.lang.Longformat中的消息value,表示该单词的最新计数。
现在,用生产者继续往streams-plaintext-input主题中发消息,输入"hello kafka streams",然后
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic streams-plaintext-input
all streams lead to kafka
hello kafka streams
在消费者命令窗口,你可以观察WordCount程序写入到输出主题的数据:
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
all 1
streams 1
lead 1
to 1
kafka 1
hello 1
kafka 2
streams 2
在这里,最后一行打印行kafka 2和streams 2表示计数已经从1递增到2。每当你向输入主题写入更多的输入消息时,你将观察到新的消息被添加到streams-wordcount-output主题,表示由WordCount应用程序计算出的最新字数。让我们输入一个最终的输入文本行“join kafka summit”,然后在控制台生产者中输入主题streams-wordcount-input之前的
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic streams-wordcount-input
all streams lead to kafka
hello kafka streams
join kafka summit
streams-wordcount-output主题随后将显示相应的更新变化(请参见最后三行):
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
all 1
streams 1
lead 1
to 1
kafka 1
hello 1
kafka 2
streams 2
join 1
kafka 3
summit 1
可以看到,Wordcount应用程序的输出实际上是一个连续的更新流,其中每个输出记录(即上面原始输出中的每一行)是单个单词的更新计数,也就是诸如“kafka”的记录关键字。 对于具有相同密钥的多个记录,每个后面的记录都是前一个记录的更新。
下面的两张图说明了幕后发生的事情。第一列显示KTable
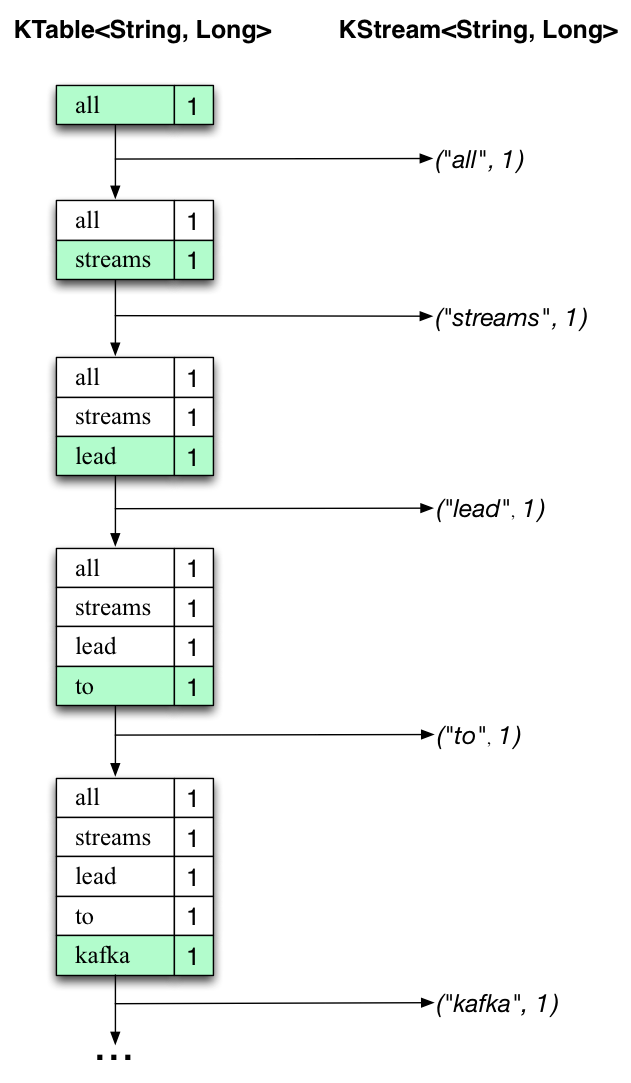
首先正在处理文本行“all streams lead to kafka”。KTable正在建立,因为每个新单词都会生成一个新表格(用绿色背景突出显示),并将相应的更改记录发送到下游KStream。
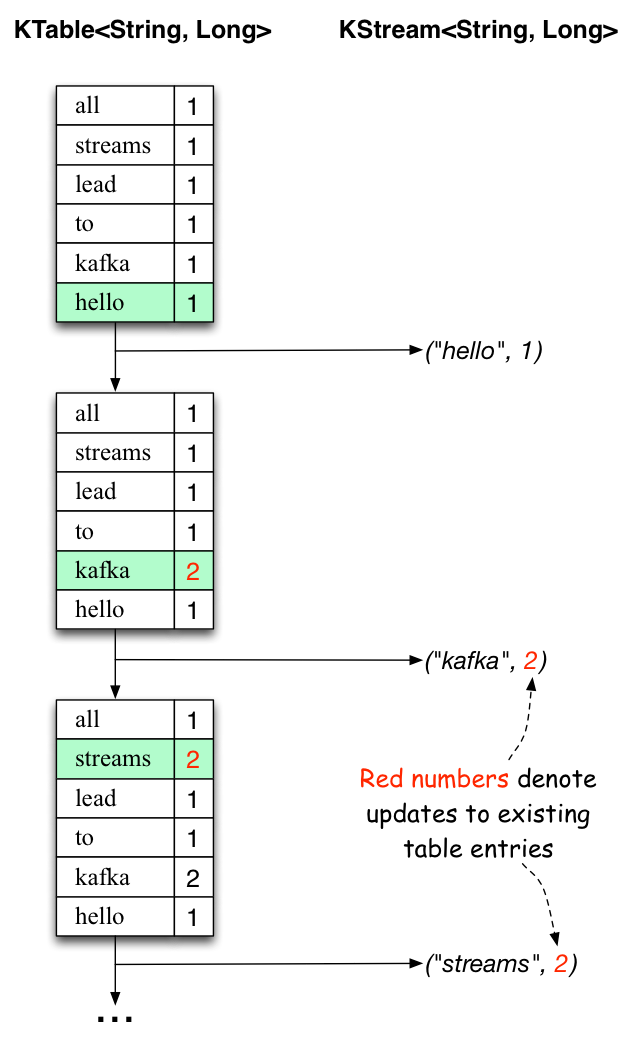
当处理第二行文本“hello kafka streams”时,我们首次观察到KTable中现有的条目正在被更新(这里是:“kafka”和“streams”)。 再次,更改记录发送到输出主题。
(我们跳过了第三行如何处理的说明)。这解释了为什么输出主题具有我们上面显示的内容,因为它包含完整的变更记录。
在这个例子的范围之外,Kafka Streams在这里做的是利用表和变更日志流之间的对偶性(这里:table = KTable,changelog stream =下游KStream):你可以发布table转换为流,并且如果你从头到尾使用整个变更日志流,则可以重新构建表的内容。
Step 6: 停止应用
最后,通过Ctrl-C停止控制台消费者,生产者,Wordcount程序,Kafka Broker和Zokeeper服务。



咨询下,使用kafkaStream 怎么集群,怎么多机部署,多台机器产生的结果如果缓存在本地结果状态,那么是否需要自己合并多机的结果,还有就是如果多机部署,其中有一台机器停掉,会导致例外一台机器的结果count 重新从0开始计算,请问怎么处理集群方面的问题
文章里有介绍用公共存储呀。
能不能留个联系方式微信QQ交流沟通下,正要上生产 集群方案有问题
企业服务,我们是收费的,不好意思额。
有什么问题,可以在问题专区里提。
如果是多个partition,那么processor会有多个线程,各有各的statestore,比如hello world发送两次,topic:wordCount有两个parttiion,那么processor会有两个,各自分析的结果就是{hello:1,world:1} , {hello:1,world:1},最后输出到一个kafka主题假设是wordCountOutput,我写一个消费者接受这个主题的消息,我还要自己去处理合并? 而且随着更多的hello world分析结果过来,都不是简单的相加那么简单,对于分析后多分区的消息归集有什么好的方案吗?
不会的,有公共存储的。
公共存储不支持logging持久化的,没有容错
Stores.create(STATE_STORE) ?
这些store是可以支持持久化的,但是new Topology().addGlobalStore()【这个就是公共存储】传入的Stores.xxxxStore()不能是enableLoggging的
if (loggingEnabled) {
throw new TopologyException("StateStore " + storeName + " for global table must not have logging enabled.");
}
也许kafka觉得全局的stateStore不需要持久化了吧,因为各个partition的statestore已经持久化了,全局的只是用于做一次归集,就算每次都计算下也不会有太大的开销
你好,我按照kafka streams官方那个统计单词数wordCounts 的案例写的实例,在往topic里面发了消息之后,运行这个streams的程序,老是报错:Exception in thread "StreamThread-1" java.lang.UnstatisfiedLinkError: C:\Users\Administrator\AppData\Local\Temp\librocksdbjni5514835249421415939.dll: Can't find dependent libraries;
请问,这个什么原因,我是通过java客户端执行的,不是命令行
我在你网站上看到一个跟我很像的案例,他也遇到这个问题了,你帮看下https://www.orchome.com/818
有人回复了,把jre从32-bit换成64-bit,问题解决。
指的是什么jre?
这个忽略
我原来装的就是64bit的jre啊。。。