日志压缩
Log compaction ensures that Kafka will always retain at least the last known value for each message key within the log of data for a single topic partition. It addresses use cases and scenarios such as restoring state after application crashes or system failure, or reloading caches after application restarts during operational maintenance. Let's dive into these use cases in more detail and then describe how compaction works.
日志压缩确保kafka始终保留至少单个topic分区数据中每条消息key的最后的值。它解决了一些用例和场景,如应用程序崩溃或系统故障后还原状态,或应用程序在运行维护过程中重新启动后重新加载缓存。让我们深入讨论这些使用中的更多细节,描述它是如何压缩的。
So far we have described only the simpler approach to data retention where old log data is discarded after a fixed period of time or when the log reaches some predetermined size. This works well for temporal event data such as logging where each record stands alone. However an important class of data streams are the log of changes to keyed, mutable data (for example, the changes to a database table).
目前为止,我们只描述了比较简单的数据保留方法,旧的数据保留一段固定的时间,或当日志达到规定的大小后丢弃。这非常适用于暂时性事件数据,如日志记录,每个记录是独立的。而是一类重要的数据流,日志是变化的,可变的数据(例如:更改数据库表)。
Let's discuss a concrete example of such a stream. Say we have a topic containing user email addresses; every time a user updates their email address we send a message to this topic using their user id as the primary key. Now say we send the following messages over some time period for a user with id 123, each message corresponding to a change in email address (messages for other ids are omitted):
让我们来讨论一个关于流的具体的例子,假设我们有一个topic里包含用户的email地址,每次用户更新他们的email地址,我们发送一条消息到这个topic,使用用户Id作为主键。现在,我们在一段时间内为id为123的用户发送一些消息,每个消息对应email地址的改变(其他ID消息省略):
123 => bill@microsoft.com
.
.
.
123 => bill@gatesfoundation.org
.
.
.
123 => bill@gmail.com
Log compaction gives us a more granular retention mechanism so that we are guaranteed to retain at least the last update for each primary key (e.g. bill@gmail.com). By doing this we guarantee that the log contains a full snapshot of the final value for every key not just keys that changed recently. This means downstream consumers can restore their own state off this topic without us having to retain a complete log of all changes.
日志压缩为我提供了更精细的保留机制,所以我们至少保留每个主键的最后一次更新 (例如:bill@gmail.com)。这样我们保证日志包含每一个key的最终值而不只是最近变更的完整快照。这意味着下游消费者可以获得最终的状态而无需拿到所有的变化的消息信息。
Let's start by looking at a few use cases where this is useful, then we'll see how it can be used.
让我们先看几个有用的用例,然后我们再看到怎么使用它。
Database change subscription. It is often necessary to have a data set in multiple data systems, and often one of these systems is a database of some kind (either a RDBMS or perhaps a new-fangled key-value store). For example you might have a database, a cache, a search cluster, and a Hadoop cluster. Each change to the database will need to be reflected in the cache, the search cluster, and eventually in Hadoop. In the case that one is only handling the real-time updates you only need recent log. But if you want to be able to reload the cache or restore a failed search node you may need a complete data set.
数据库更改订阅,通常需要在多个数据库系统,有一个数据集,这些系统中通常有一个是某种类型的数据库(无论是RDBMS或者新流行的key-value仓库)。例如,你可能有一个数据库,缓存,搜索集群,以及Hadoop集群。每次变更数据库,也同时需要变更缓存,搜索集群,和Hadoop。在只需处理最新日志的实时更新的情况下,你只需要最近的日志。但是,如果你希望能够重新加载缓存或恢复搜索失败的节点,你可能需要一个完整的数据集。Event sourcing. This is a style of application design which co-locates query processing with application design and uses a log of changes as the primary store for the application.
事件源。查询处理与应用设计共存,这是一种应用程序的设计风格,并使用一个变更日志作为应用程序的主仓库。Journaling for high-availability. A process that does local computation can be made fault-tolerant by logging out changes that it makes to its local state so another process can reload these changes and carry on if it should fail. A concrete example of this is handling counts, aggregations, and other "group by"-like processing in a stream query system. Samza, a real-time stream-processing framework, uses this feature for exactly this purpose.
高可用的日志:本地的计算进程可以通过注销它自己的本地状态的变更进行容错。使另一个进程可以重载加载这些更改并继续执行(如果它故障)。例如:处理计数、聚合和其他的“group by”,- 像流查询系统。Samza,实时流处理框架,使用这个特性正是出于这一原因。
In each of these cases one needs primarily to handle the real-time feed of changes, but occasionally, when a machine crashes or data needs to be re-loaded or re-processed, one needs to do a full load. Log compaction allows feeding both of these use cases off the same backing topic. This style of usage of a log is described in more detail in this blog post.
在每一种情况下,首先需要去处理实时变更的feed(ps:新请求来的消息),但是偶尔,当机器崩溃或数据需要重新加载或重新处理时,需要做完整的加载。数据压缩允许feed这2种用例,这种风格的更详细的请看博客帖子。
The general idea is quite simple. If we had infinite log retention, and we logged each change in the above cases, then we would have captured the state of the system at each time from when it first began. Using this complete log we could restore to any point in time by replaying the first N records in the log. This hypothetical complete log is not very practical for systems that update a single record many times as the log will grow without bound even for a stable dataset. The simple log retention mechanism which throws away old updates will bound space but the log is no longer a way to restore the current state—now restoring from the beginning of the log no longer recreates the current state as old updates may not be captured at all.
通常想法是很简单,如果我们有无限的日志保留,我们记录每个变更,在上述的情况下,那么我们就从当它第一次开始每次捕获系统状态。保留完整日志,我们可以通过在日志重放第一个N记录来恢复到任意的时间点。这个假设的完整的日志对单条记录更新多次的系统是很不实用,即使是一个稳定的数据集,但日志将无线增长。一个简单的机制是扔掉旧日志,但是日志不能在恢复了。
The general idea is quite simple. If we had infinite log retention, and we logged each change in the above cases, then we would have captured the state of the system at each time from when it first began. Using this complete log, we could restore to any point in time by replaying the first N records in the log. This hypothetical complete log is not very practical for systems that update a single record many times as the log will grow without bound even for a stable dataset. The simple log retention mechanism which throws away old updates will bound space but the log is no longer a way to restore the current state—now restoring from the beginning of the log no longer recreates the current state as old updates may not be captured at all.
日志压缩是一种机制给每条细粒度的保留,而不是基于时间的粗粒度的保留,是有选择地删除记录,我们保留相同的主键的最新记录。这种方式的日志保证至少有每个key的最后状态。
This retention policy can be set per-topic, so a single cluster can have some topics where retention is enforced by size or time and other topics where retention is enforced by compaction.
可以为每个topic设置保存策略,可以通过大小或时间,以及通过其他的压缩方式保存。
This functionality is inspired by one of LinkedIn's oldest and most successful pieces of infrastructure—a database changelog caching service called Databus. Unlike most log-structured storage systems Kafka is built for subscription and organizes data for fast linear reads and writes. Unlike Databus, Kafka acts as a source-of-truth store so it is useful even in situations where the upstream data source would not otherwise be replayable.
此功能的灵感来自LinkedIn最古老和最成功的基础设施 — 一个叫做Databus的 “数据库更新日志缓存服务”。不像大多数日志结构的存储系统,Kafka是专门为订阅和快速线性的读和写的组织数据,不同与Databus,kafka作为source-of-truth(真源:这里简单解释一下,消息发送到kafka这里,那么kafka里的消息就是最真的源了,因为如果kafka宕机了,从kafka的角度来讲,那kafka能自己恢复消息吗?不能,因为它不知道找谁,因此,kafka里面的消息就是真的源头数据),因此非常利于那些上游数据无法回放的情形。
日志压缩基础
Here is a high-level picture that shows the logical structure of a Kafka log with the offset for each message.
这是一个高级别的日志逻辑图,展示了kafka日志的每条消息的offset逻辑结构。
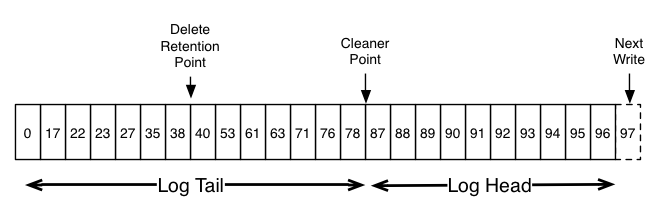
The head of the log is identical to a traditional Kafka log. It has dense, sequential offsets and retains all messages. Log compaction adds an option for handling the tail of the log. The picture above shows a log with a compacted tail. Note that the messages in the tail of the log retain the original offset assigned when they were first written—that never changes. Note also that all offsets remain valid positions in the log, even if the message with that offset has been compacted away; in this case this position is indistinguishable from the next highest offset that does appear in the log. For example, in the picture above the offsets 36, 37, and 38 are all equivalent positions and a read beginning at any of these offsets would return a message set beginning with 38.
日志的头部(head)和kafka日志一样,也是密集连续的offset,并保存所有的消息。日志压缩增加了一个选项来处理尾部(tail)的日志,上图显示了一个尾部压缩日志。另外,日志尾部已分配的消息将保留原来的偏移量 —— 永远不会改变,还要注意,在日志中所有的偏移量仍然保持有效的位置,即使消息已经压缩,在这种情况下,在日志的下一个最高的offset的位置是无法区分的。例如,上图的偏移量36,37和38都是等效的位置,读这些offset都将返回消息集的开始位置38。
Compaction also allows for deletes. A message with a key and a null payload will be treated as a delete from the log. Such a record is sometimes referred to as a tombstone. This delete marker will cause any prior message with that key to be removed (as would any new message with that key), but delete markers are special in that they will themselves be cleaned out of the log after a period of time to free up space. The point in time at which deletes are no longer retained is marked as the "delete retention point" in the above diagram.
压缩也允许删除。通过消息的key和空负载(null payload)来标识该消息可从日志中删除。这个删除标记将导致删除在这个key之前的任何消息(以及该key的所有新消息)。但是删除标记是特殊的,他们自己去清理日志,在一段时间之后释放空间。在删除的时候不再保留标记作为“删除保存点”,如上图。
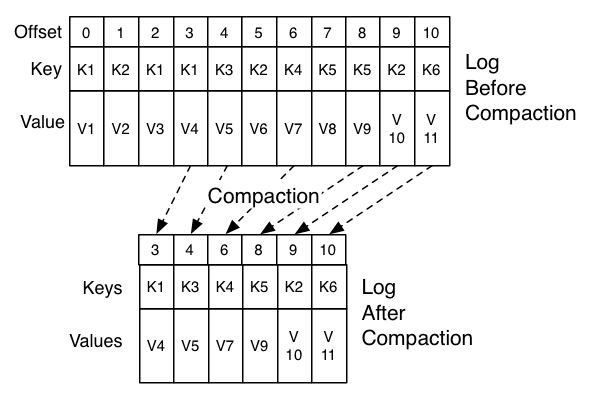
The compaction is done in the background by periodically recopying log segments. Cleaning does not block reads and can be throttled to use no more than a configurable amount of I/O throughput to avoid impacting producers and consumers. The actual process of compacting a log segment looks something like this:
压缩是在后台通过定期重新复制日志段来完成的。清洗不会阻塞读,可以限流I/O吞吐量(是可配置),以避免影响生产者和消费者。实际压缩处理日志看起来像这样:
日志压缩提供什么保障?
Log compaction guarantees the following:
日志压缩保障如下:
Any consumer that stays caught-up to within the head of the log will see every message that is written; these messages will have sequential offsets. The topic's min.compaction.lag.ms can be used to guarantee the minimum length of time must pass after a message is written before it could be compacted. I.e. it provides a lower bound on how long each message will remain in the (uncompacted) head. The topic's max.compaction.lag.ms can be used to guarantee the maximum delay between the time a message is written and the time the message becomes eligible for compaction.
任何滞留在日志head中的所有消费者能看到写入的所有消息;这些消息都是有序的offset。topic的使用min.compaction.lag.ms用来保障消息写入之前必须经过的最小时间长度,才能被压缩。也就是说,它提供了消息保留在head(未压缩)的最少时间。Ordering of messages is always maintained. Compaction will never re-order messages, just remove some.
始终保持消息的排序。压缩永远不会重新排序消息,只是删除了一些。The offset for a message never changes. It is the permanent identifier for a position in the log.
消息的偏移量永远不会改变。消息在日志中的位置将永久保存。Any consumer progressing from the start of the log will see at least the final state of all records in the order they were written. Additionally, all delete markers for deleted records will be seen, provided the consumer reaches the head of the log in a time period less than the topic's delete.retention.ms setting (the default is 24 hours). In other words: since the removal of delete markers happens concurrently with reads, it is possible for a consumer to miss delete markers if it lags by more than delete.retention.ms.
从日志开始消费的所有消费者将至少看到其按顺序写入的最终状态的消息。此外,假如消费者在小于topic的delete.retention.mssetting设置的时间段(默认24小时)到达日志的head。将会看到所有已删除消息的删除标记。换句话说:由于删除日志与读取同时发生,消费者将优于删除。
日志压缩的细节
Log compaction is handled by the log cleaner, a pool of background threads that recopy log segment files, removing records whose key appears in the head of the log. Each compactor thread works as follows:
日志cleaner处理日志压缩,后台线程池重新复制日志段文件,移除在日志head中出现的消息。每个压缩线程工作方式如下:
It chooses the log that has the highest ratio of log head to log tail
选择log head(日志头)到log tail(日志尾)比率最高的日志。
It creates a succinct summary of the last offset for each key in the head of the log
在head日志中为每个key的最后offset创建一个的简单概要。
It recopies the log from beginning to end removing keys which have a later occurrence in the log. New, clean segments are swapped into the log immediately so the additional disk space required is just one additional log segment (not a fully copy of the log).
它从日志的开始到结束,删除那些在日志中最新出现的key,新的,干净的段将立刻交换到日志中。因此,所需的额外磁盘空间只是一个额外的日志段(不是日志的完整副本)。
The summary of the log head is essentially just a space-compact hash table. It uses exactly 24 bytes per entry. As a result with 8GB of cleaner buffer one cleaner iteration can clean around 366GB of log head (assuming 1k messages).
日志head的概要本质上是一个空间密集型的哈希表,每个entry使用固定的24byte。这样8GB的cleaner buffer一次迭代可清理大约366GB的日志(假设消息1K)。
配置Log Cleaner
The log cleaner is enabled by default. This will start the pool of cleaner threads. To enable log cleaning on a particular topic you can add the log-specific property
Log cleaner默认是启动的。也将启动cleaner线程池。你也可以针对特定topic启用log清洁,通过
log.cleanup.policy=compact
This can be done either at topic creation time or using the alter topic command.
可以在创建topic时或使用alter topic命令指定。
The log cleaner can be configured to retain a minimum amount of the uncompacted "head" of the log. This is enabled by setting the compaction time lag.
log cleaner可以配置保留日志“head”不压缩的最小数。通过设置压缩延迟时间。
log.cleaner.min.compaction.lag.ms
This can be used to prevent messages newer than a minimum message age from being subject to compaction. If not set, all log segments are eligible for compaction except for the last segment, i.e. the one currently being written to. The active segment will not be compacted even if all of its messages are older than the minimum compaction time lag.
这可以预防消息在一个最小消息时间绝不会被压缩。如果不设置,除了最新的段,其他所有的段都是可以压缩的,即,当前正在写入的那个。即使其所有消息都比最小压缩时间滞后更长,正在写入的段也不会被压缩。
Further cleaner configurations are described here.
关于cleaner更详细的配置在这里。



的kafka日志。 这句话没翻译完
感谢提醒,已更新。
大佬你好,请问在日志压缩的细节中“选择log head(日志头)到log tail(日志尾)比率最高的日志”,怎么理解比率最高呢?
理解成,频率最高吧
大佬你好,麻烦问下,“它从日志的开始到结束,删除那些在日志中最新出现的key,新的,干净的段将立刻交换到日志中”,这句话具体是什么意思=_=
这种场景是,比如,你的邮箱号从 123@qq.com 更改为 456@qq.com 到最后一次的 789@qq.com,只保留最后一个,其他的没有用了。
请教一下,我想要知道log compact的性能如何?我如何能知道
我们旧可以通过在日志重放第一个N记录来恢复到任意的时间点,楼主这里有个错别字,旧、就
感谢指正,已更正。
这里讲的压缩是compression.codec这个配置吗
好几个 你可以在broker配置搜索关键字
怎么测试啊?