9. Kafka Streams
9.1 概述
Kafka Streams是一个客户端程序库,用于处理和分析存储在Kafka中的数据,并将得到的数据写回Kafka或发送到外部系统。Kafka Stream基于一个重要的流处理概念。如正确的区分事件时间和处理时间,窗口支持,以及简单而有效的应用程序状态管理。Kafka Streams的入口门槛很低: 你可以快速的编写和在单台机器上运行一个小规模的概念证明(proof-of-concept);而你只需要运行你的应用程序部署到多台机器上,以扩展高容量的生产负载。Kafka Stream利用kafka的并行模型来透明的处理相同的应用程序作负载平衡。
Kafka Stream 的亮点:
设计一个简单的、轻量级的客户端库,可以很容易地嵌入在任何java应用程序与任何现有应用程序封装集成。
Apache Kafka本身作为内部消息层,没有外部系统的依赖,还有,它使用kafka的分区模型水平扩展处理,并同时保证有序。
支持本地状态容错,非常快速、高效的状态操作(如join和窗口的聚合)。
采用 one-recored-at-a-time(一次一个消息) 处理以实现低延迟,并支持基于事件时间(event-time)的窗口操作。
提供必要的流处理原语(primitive),以及一个 高级别的Steram DSL 和 低级别的Processor API。
9.2 核心概念
我们首先总结Kafka Streams的关键概念。
Stream处理拓扑
流是Kafka Stream提出的最重要的抽象概念:它表示一个无限的,不断更新的数据集。流是一个有序的,可重放(反复的使用),不可变的容错序列,数据记录的格式是键值对(key-value)。通过Kafka Streams编写一个或多个的计算逻辑的处理器拓扑。其中处理器拓扑是一个由流(边缘)连接的流处理(节点)的图。
流处理器是处理器拓扑中的一个节点;它表示一个处理的步骤,用来转换流中的数据(从拓扑中的上游处理器一次接受一个输入消息,并且随后产生一个或多个输出消息到其下游处理器中)。
在拓扑中有两个特别的处理器:
源处理器(Source Processor):源处理器是一个没有任何上游处理器的特殊类型的流处理器。它从一个或多个kafka主题生成输入流。通过消费这些主题的消息并将它们转发到下游处理器。Sink处理器:sink处理器是一个没有下游流处理器的特殊类型的流处理器。它接收上游流处理器的消息发送到一个指定的Kafka主题。
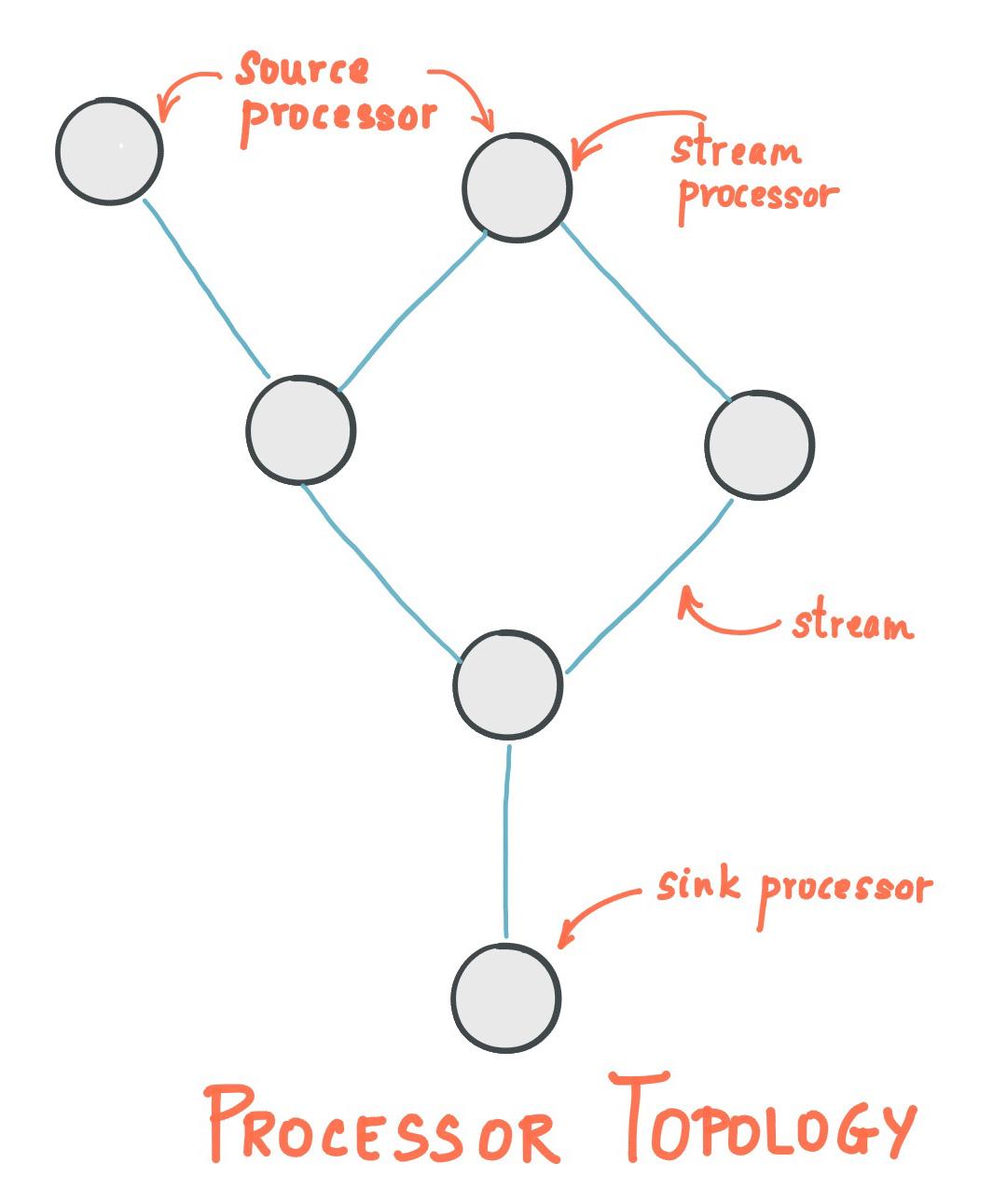
Kafka streams提供2种方式来定义流处理器拓扑:Kafka Streams DSL提供了更常用的数据转换操作,如map和filter;低级别Processor API允许开发者定义和连接自定义的处理器,以及和状态仓库交互。
处理器拓扑仅仅是流处理代码的逻辑抽象。
时间
在流处理方面有一个重要的时间概念,以及它是如何建模和集成。例如:一些操作,如基于时间界限定义的窗口。
时间在流中的常见概念如下:
事件时间 - 当一个事件或数据记录发生的时间点,就是最初创建的“源头”。
处理时间 - 事件或数据消息发生在
流处理应用程序处理的时间点。即,记录已被消费。处理时间可能是毫秒,小时,或天等。比原始事件时间要晚。摄取时间 - 事件或数据记录是Kafka broker存储在topic分区的时间点。与事件时间的差异是,当记录由Kafka broker追加到目标topic时,生成的摄取时间戳,而不是消息创建时间(“源头”)。与处理时间的差异是处理时间是流处理应用处理记录时的时间。比如,如果一个记录从未被处理,那么久没有处理时间,但仍然有摄取时间。
Kafka Streams通过TimestampExtractor接口为每个数据记录分配一个时间戳。该接口的具体实现了基于数据记录的实际内容检索或计算获得时间戳,例如嵌入时间戳字段提供的事件时间语义,或使用其他的方法,比如在处理时返回当前的wall-clock(墙钟)时间,从而产生了流应用程序的处理时间语义。因此开发者可以根据自己的业务需要选择执行不同的时间。例如,每条记录时间戳描述了流的时间增长(尽管记录在stream中是无序的)并利用时间依赖性来操作,如join。
最后,当一个Kafka Streams应用程序写入记录到kafka时,它将分配时间戳到新的消息。时间戳分配的方式取决于上下文:
当通过处理一些输入记录(例如,在process()函数调用中触发的context.forward())生成新的输出记录时,输出记录时间戳直接从输入记录时间戳继承。
当通过周期性函数(如punctuate())生成新的输出记录时。输出记录时间戳被定义为流任务的当前内部时间(通过context.timestamp()获取)。
对于聚合,生成的聚合更新的记录时间戳将被最新到达的输入记录触发更新。
状态
一些流处理程序不需要状态,这意味着消息处理是独立于其他的消息处理的。但是呢,能够保持状态,这为复杂的流处理程序打开了许多可能性:你可以加入输入流,或分组和汇总数据记录等。Streams DSL提供了许多如状态性的操作。
Kafka Stream提供了所谓的状态存储,流处理程序可以用来存储和查询数据。这是一个重要的能力。在Kafka Stream中的每一个任务嵌入了一个或多个状态存储,可通过API来存储和查询处理所需的数据。状态存储可以是一个持久的key/value存储,内存中的HashMap,或者是其他的数据结构。Kafka Stream提供了本地状态存储的故障容错和自动恢复。
正如我们上面提到的,Kafka Streams应用程序的计算逻辑被定义为一个处理器拓扑。目前,Kafka Streams提供2个API来定义处理器拓扑,将在下面的章节中讨论。
9.3 ARCHITECTURE(架构)
Kafka Streams通过生产者和消费者,并利用kafka自有的能力来提供数据平行性,分布式协调性,故障容错和操作简单性,从而简化了应用程序的开发,在本节中,我们将描述kafka Streams是如何工作的。
下图展示了Kafka Streams应用程序的解剖图,让我们来看一些细节。
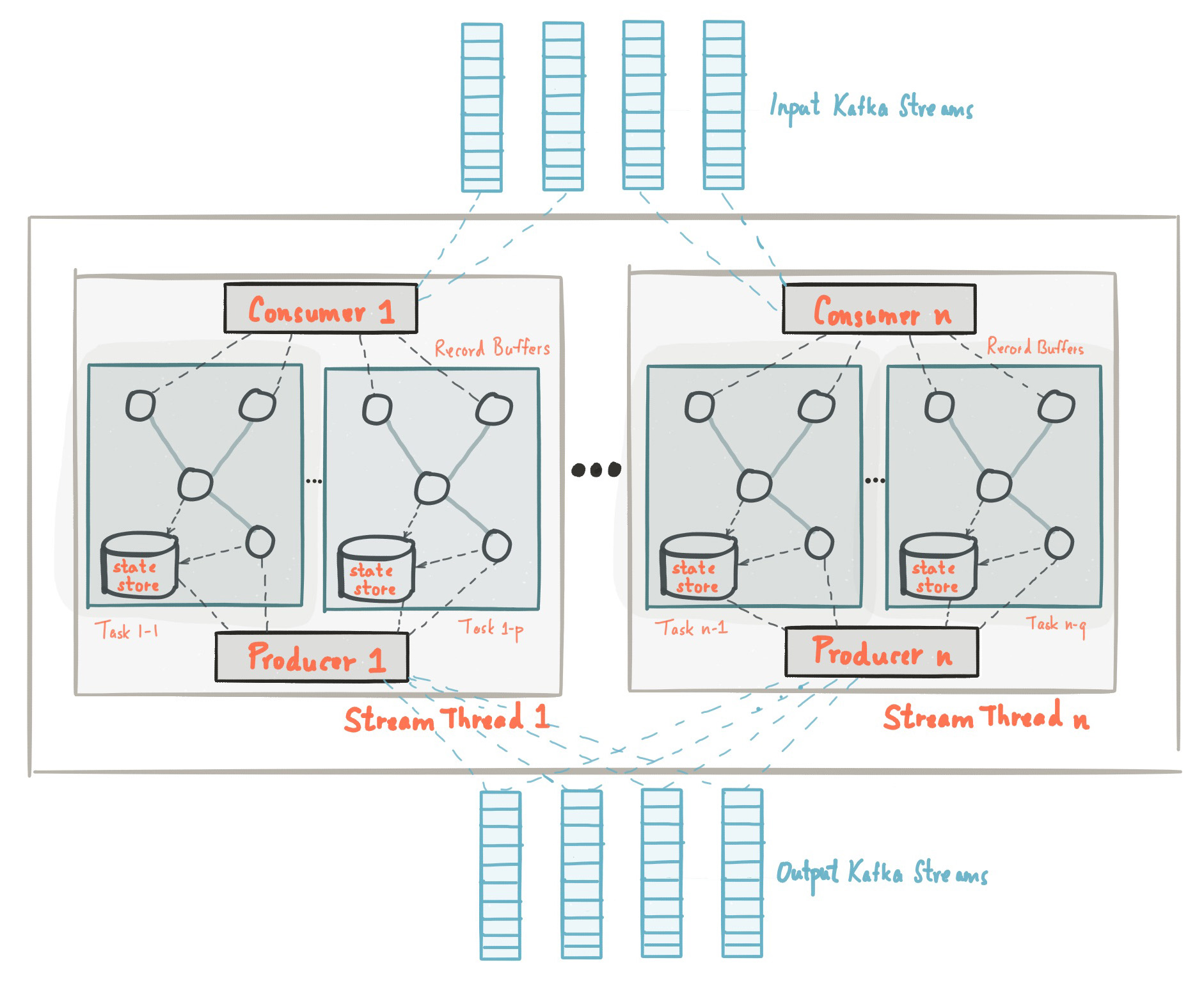
Stream分区和任务
Kafka分区数据的消息层用于存储和传输。Kafka Streams分区数据用于处理。 在这两种情况下,这种分区使数据弹性,可扩展,高性能和容错。Kafka Streams使用了分区和任务的概念,基于Kafka主题分区的并行性模型。在并发环境行,Kafka Streams和Kafka之间有着紧密的联系:
- 每个流分区是完全有序的数据记录队列,并映射到kafka主题的分区。
- 流的数据消息与主题的消息映射。
- 数据记录中的keys决定了Kafka和Kafka Streams中数据的分区,即,如何将数据路由到指定的分区。
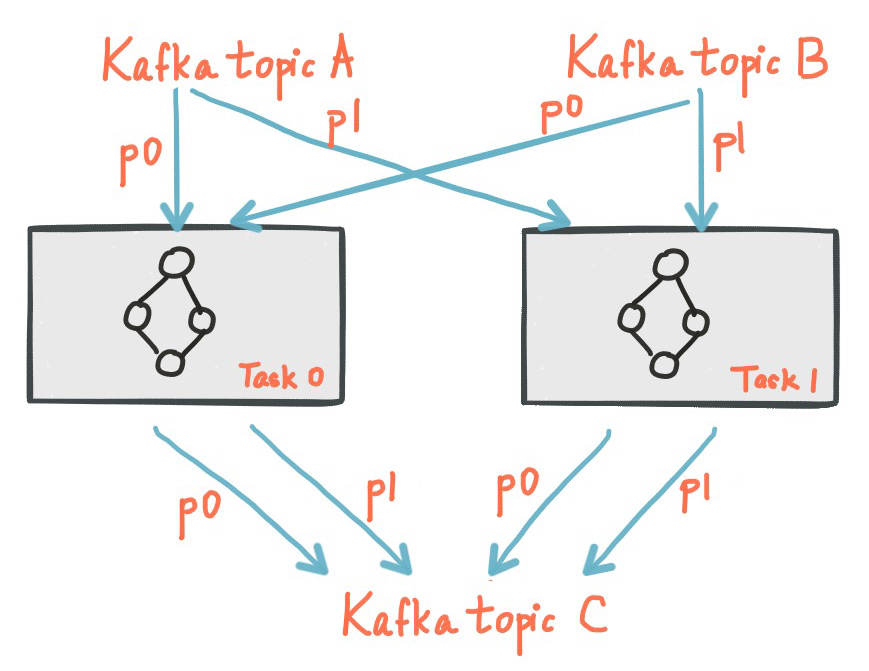
应用程序的处理器拓扑通过将其分成多个任务来进行扩展,更具体点说,Kafka Streams根据输入流分区创建固定数量的任务,其中每个任务分配一个输入流的分区列表(即,Kafka主题)。分区对任务的分配不会改变,因此每个任务是应用程序并行性的固定单位。然后,任务可以基于分配的分区实现自己的处理器拓扑;他们还可以为每个分配的分区维护一个缓冲,并从这些记录缓冲一次一个地处理消息。作为结果,流任务可以独立和并行的处理而无需手动干预。
重要的是要理解Kafka Streams不是资源管理器,而是可在任何地方都能“运行”的流处理应用程序库。多个实例的应用程序在同一台机器上执行,或分布多个机器上,并且任务可以通过该库自动的分发到这些运行的实例上。分区对任务的分配永远不会改变;如果一个应用程式实例失败,则其被分配的任务将自动地在其他的实例重新创建,并从相同的流分区继续消费。
下面展示了2个分区,每个任务分配了输出流的1个分区。
线程模型
Kafka Streams允许用户配置线程数,可用于平衡处理应用程序的实例。每个线程的处理器拓扑独立的执行一个或多个任务。例如,下面展示了一个流线程运行2个流任务。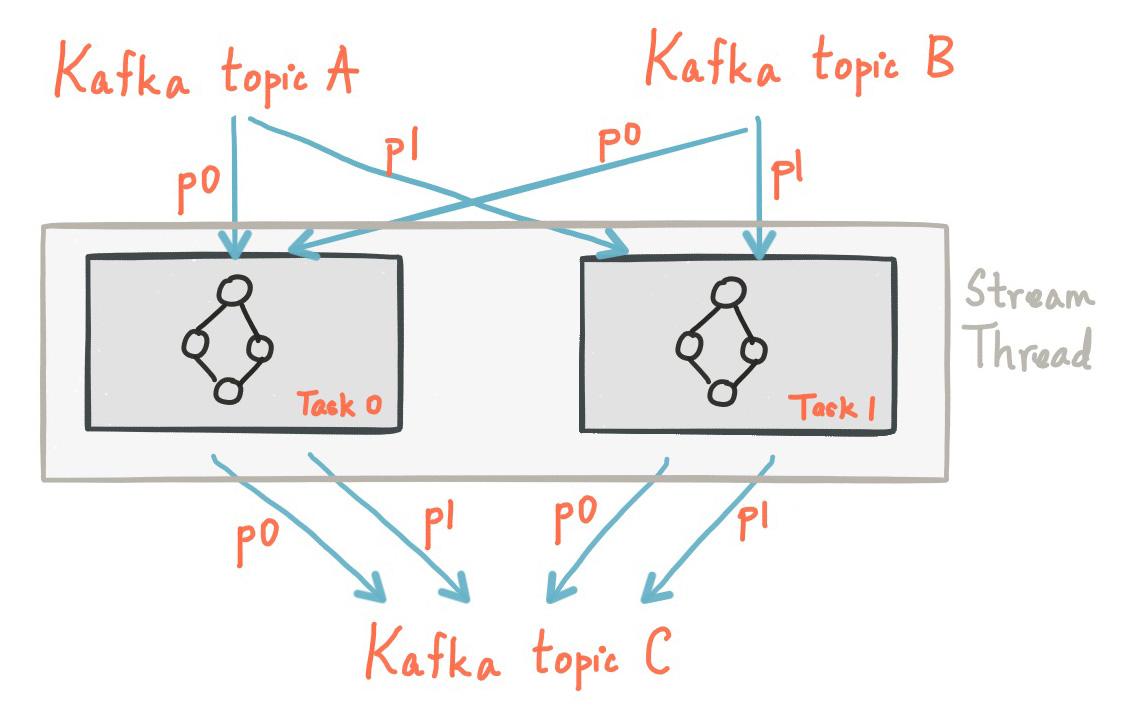
启动更多的流线程或更多应用程序实例,只需复制拓扑逻辑(ps,就是多复制几个代码到不同的机器上运行),达到并行处理处理不同的Kafka分区子集的目的。要注意的是,这些线程之间不共享状态。因此无需协调内部的线程。这使它非常简单在应用实例和线程之间并行拓扑。Kafka主题分区的分配是通过Kafka Streams利用Kafka的协调功能在多个流线程之间透明处理。
如上所述,Kafka Streams扩展流处理应用程序是很容易的:你只需要运行你的应用程序实例,Kafka Streams负责在实例中运行的任务之间分配分区。你可以启动和应用程序线程一个多的输入Kafka主题分区。这样,所有运行中的应用实例,每个线程(或更确切的说,它运行的任务)至少有一个输入分区可以处理。
本地状态存储
存储,其实是流处理器应用程序可用来存储和查询数据,对于实现状态性操作是一个很重要的能力。例如,当你调用状态性操作时,如 join()或aggregate(),或当你在窗口化流时,Kafka Streams DSL会自动创建和管理这些状态存储。
在Kafka Streams应用程序的每个流任务可以键入一个或多个本地状态存储,这些本地状态存储可以通过API存储和查询处理所需的数据。Kafka Streams也为本地状态存储提供了容错和自动恢复的能力。
下图显示了两个流任务及其专用本地状态存储。
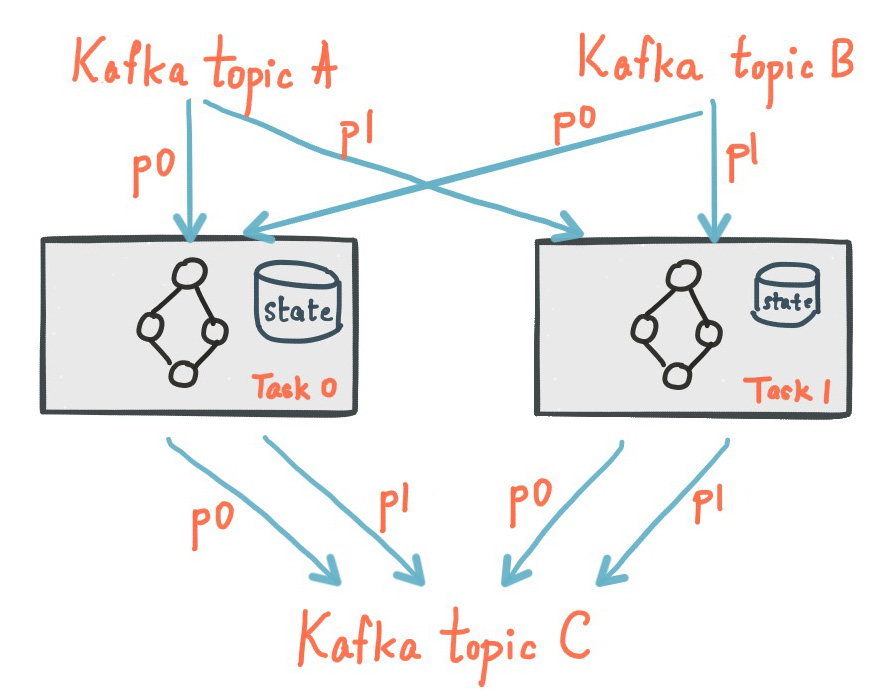
故障容错
Kafka Streams基于Kafka分区的高可用和副本故障容错能力。因此,当流数据持久到Kafka,即使应用程序故障,如果需要重新处理它,它也是可用的。Kafka Streams中的任务利用Kafka消费者客户端提供的故障容错的能力来处理故障。如果任务故障,Kafka Streams将自动的在剩余运行中的应用实例重新启动该任务。
此外,Kafka Streams还确保了本地状态仓库对故障的稳定性。对于每个状态仓库都维持一个追踪所有的状态更新的变更日志主题。这些变更日志主题也分区,因此,每个本地状态存储实例,任务访问仓里,都有自己的专用的变更日志分区。变更主题日志也启用了日志压缩,以便可以安全的清除旧数据,以防止主题无限制的增长。如果任务失败并在其他的机器上重新运行,则Kafka Streams在恢复新启动的任务进行处理之前,重放相应的变更日志主题,保障在故障之前将其关联的状态存储恢复。故障处理对于终端用户是完全透明的。
请注意,任务(重新)初始化的成本通常主要取决于通过重放状态仓库变更日志主题来恢复状态的时间。为了减少恢复时间,用户可以配置他们的应用程序增加本地状态的备用副本(即。完全的复制状态)。当一个任务迁移发生时,Kafka Streams尝试去分配任务给应用实例。其中这样的备用副本已经存在,为了减少任务(重新)初始化的成本,请参见Kafka Streams配置章节的num.standby.replicas。
9.4 开发者指南
一个快速入门的示例代码,提供了如何运行一个流处理程序。本节重点介绍如何编写,配置和执行Kafka Streams应用程序。
低级别处理器API
Processor(处理器)
开发者可以通过Processor接口来实现自己的自定义处理逻辑,接口提供了 process 和 punctuate 方法。process方法执行接收的消息;并根据时间进行周期性地执行punctuate方法。此外,在init初始化方法中。processor可以保持当前的ProcessorContext实例变量,利用上下文来计划周期地(context().schedule)puncuation,转发修改后的/新的键值对(key-value)到下游系统(context().forward),提交当前的处理进度(context().commit),等。
public class MyProcessor extends Processor {
private ProcessorContext context;
private KeyValueStore kvStore;
@Override
@SuppressWarnings("unchecked")
public void init(ProcessorContext context) {
this.context = context;
this.context.schedule(1000);
this.kvStore = (KeyValueStore) context.getStateStore("Counts");
}
@Override
public void process(String dummy, String line) {
String[] words = line.toLowerCase().split(" ");
for (String word : words) {
Integer oldValue = this.kvStore.get(word);
if (oldValue == null) {
this.kvStore.put(word, 1);
} else {
this.kvStore.put(word, oldValue + 1);
}
}
}
@Override
public void punctuate(long timestamp) {
KeyValueIterator iter = this.kvStore.all();
while (iter.hasNext()) {
KeyValue entry = iter.next();
context.forward(entry.key, entry.value.toString());
}
iter.close();
context.commit();
}
@Override
public void close() {
this.kvStore.close();
}
};
在上面的代码实现中,执行了以下的操作:
在
init方法,定义每1秒调度 punctuate ,并检索名为“Counts”的本地状态存储。在
process方法中,每个接收一个记录,将字符串的值分割成单词,并更新他们的数量到状态存储(稍后我们将讨论这个特性的部分)。在
puncuate方法,迭代本地状态仓库并发送总量数到下游的处理器,并提交当前的流状态。
Processor Topology(处理器拓扑)
通过Processor API定义的自定义的处理器,开发人员将使用TopologyBuilder通过连接这些处理器共同构建一个处理器拓扑。(类似于主方法)
TopologyBuilder builder = new TopologyBuilder();
builder.addSource("SOURCE", "src-topic")
.addProcessor("PROCESS1", MyProcessor1::new /* the ProcessorSupplier that can generate MyProcessor1 */, "SOURCE")
.addProcessor("PROCESS2", MyProcessor2::new /* the ProcessorSupplier that can generate MyProcessor2 */, "PROCESS1")
.addProcessor("PROCESS3", MyProcessor3::new /* the ProcessorSupplier that can generate MyProcessor3 */, "PROCESS1")
.addSink("SINK1", "sink-topic1", "PROCESS1")
.addSink("SINK2", "sink-topic2", "PROCESS2")
.addSink("SINK3", "sink-topic3", "PROCESS3");
上面代码,是通过几个步骤来构建拓扑:
首先,所有的源节点命名为“SOURCE”并使用
addSource方法添加到拓扑中,主题“src-topic”来提供记录(消息)。3个processor节点,使用addProcessor方法添加;这里的第一个processor是”SOURCE”节点的子节点,但是其他两个
处理器的父类。最后,使用addSink方法将3个sink节点添加到完整的拓扑中。每个管道从不同父类处理器节点输出到不同的topic。
本地状态存储
请注意,Processor API不仅限于当有消息到达时候调用process()方法,也可以保存记录到本地状态仓库(如汇总或窗口连接)。利用这个特性,开发者可以使用StateStore接口定义一个状态仓库(Kafka Streams库也有一些扩展的接口,如KeyValueStore)。在实际开发中,开发者通常不需要从头开始自定义这样的状态仓库,可以很简单使用Stores工厂来设定状态仓库是持久化的或日志备份等。在下面的例子中,创建一个名为”Counts“的持久化的key-value仓库,key类型String和value类型Long。
StateStoreSupplier countStore = Stores.create("Counts")
.withKeys(Serdes.String())
.withValues(Serdes.Long())
.persistent()
.build();
为了利用这些状态仓库,开发者可以在构建处理器拓扑时使用TopologyBuilder.addStateStore方法来创建本地状态,并将它与需要访问它的处理器节点相关联,或者也可以通过TopologyBuilder.connectProcessorAndStateStores将创建的状态仓库与现有的处理器节点连接。
TopologyBuilder builder = new TopologyBuilder();
builder.addSource("SOURCE", "src-topic")
.addProcessor("PROCESS1", MyProcessor1::new, "SOURCE")
// create the in-memory state store "COUNTS" associated with processor "PROCESS1"
.addStateStore(Stores.create("COUNTS").withStringKeys().withStringValues().inMemory().build(), "PROCESS1")
.addProcessor("PROCESS2", MyProcessor3::new /* the ProcessorSupplier that can generate MyProcessor3 */, "PROCESS1")
.addProcessor("PROCESS3", MyProcessor3::new /* the ProcessorSupplier that can generate MyProcessor3 */, "PROCESS1")
// connect the state store "COUNTS" with processor "PROCESS2"
.connectProcessorAndStateStores("PROCESS2", "COUNTS");
.addSink("SINK1", "sink-topic1", "PROCESS1")
.addSink("SINK2", "sink-topic2", "PROCESS2")
.addSink("SINK3", "sink-topic3", "PROCESS3");
在下一节,我们使用另一种方式来构建处理器拓扑:Kafka Streams DSL
高级别Streams DSL
使用Streams DSL构建一个处理器拓扑,开发者可以使用KStreamBuilder类,它是TopologyBuilder的扩展。在Kafka源码的streams/examples包中有一个简单的例子。另外本节剩余的部分将通过一些代码来展示使用Streams DSL创建拓扑的关键的步骤。但是我们推荐开发者阅读更详细完整的源码。
Duality of Streams and Tables(流和表的对偶性)
我们讨论Kafka Streams聚合等概念之前,我们必须首先介绍表,和最重要的表和流之间的关系:所谓的流表对偶性。本质上,这种二元性意味着一个流可以被视为一个表,反之亦然。例如,Kafka的日志压缩功能也利用了对偶性。
表的格式是一个简单的key-value对的集合,也称为map或关系数组。看起来像这样:
流表二元性描述了流和表之间的紧密关系。
流作为表:一个流可以认为是一个表的变更日志,其中在流中的每个的数据记录捕获表的状态变化。因此,流其实是一个伪装的表,并且可以通过从开始到结束重放变更日志来很容地重构“真实”表。同样,在更多类比中,在流中聚合数据记录 - 例如根据用户的访问事件统计总量。- 将返回一个表。(这里的key和value分别是用户和其对应的网页游览量。)表作为流:表可以认为是在流中的每个key的最新value的一个时间点的快照(流的数据记录是key-value对)。因此,表也可以认为是伪装的流,它可以通过对表中每个key-value进行迭代而容易的转换成“真实”流。
让我们用一个例子来说明这一点,假设有一张表,用于跟踪用户的总游览量(下图第一列)。随着时间的推移,每当处理新的网页游览时,相应的更新表的状态。这里,不同时间点之间状态的改变 - 以及表的不同的更新- 表示为变更日志流(第二列)。
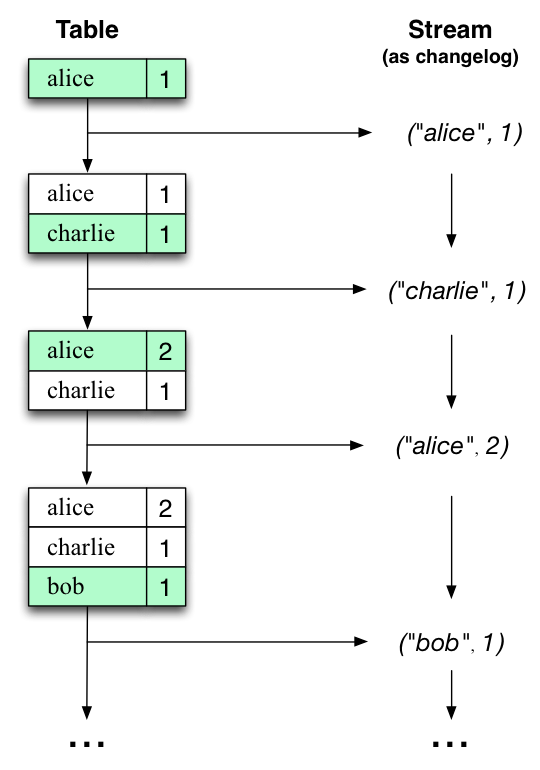
有趣的是,由于流表的对偶性,同一个流可以用来重建原始表(第三列):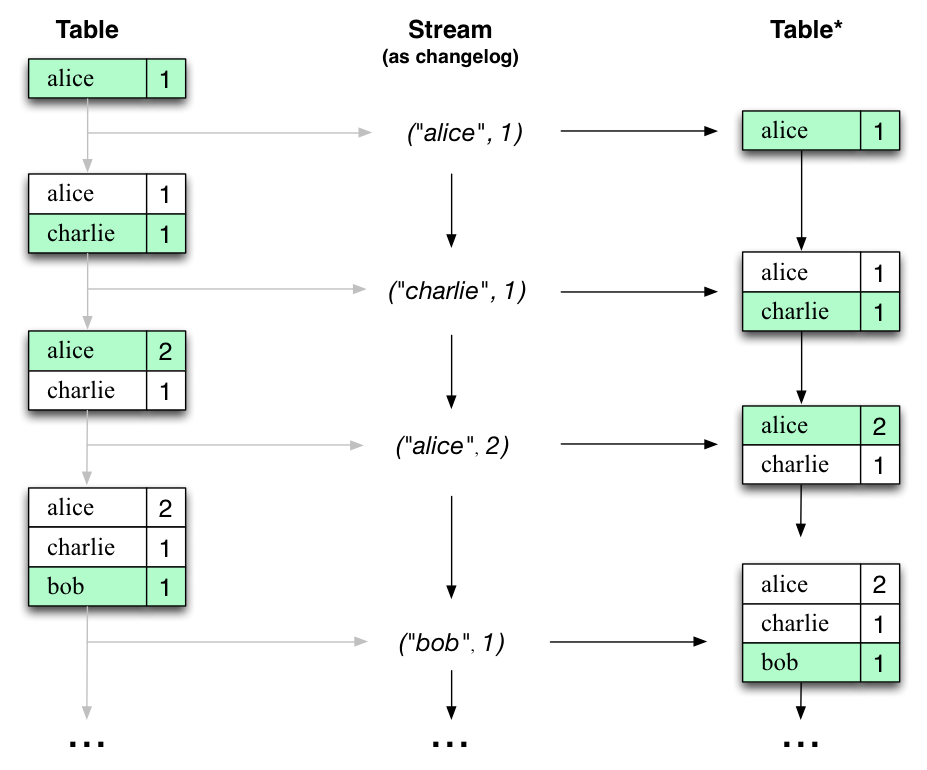
例如,使用相同的机制,通过变更日志捕获(CDC)复制数据库,并在Kafka Streams中,在机器之间复制其所谓的状态存储,以实现容错。
流表的对偶性是一个重要的概念,Kafka Streams通过KStream,KTable,和GlobalKTable接口模型。我们将在下面的章节中描述。
KStream, KTable, GlobalKTable
DSL有3个主要的抽象概念。KStream是一个消息流抽象,其中每个数据记录代表在无界数据集里的自包含数据。KTable是一个变更日志流的抽象,其中每个数据记录代表一个更新。更确切的说,数据记录中的value是相同记录key的最后一条的更新(如果key存在,如果key还不存在,则更新将被认为是创建)。类似于Ktable,GlobalKTable也是一个变更日志流的抽象。其中每个数据记录代表一个更新。但是,不同于KTable,它是完全的复制每个KafkaStreams实例。同样,GlobalKTable也提供了通过key查找当前数据值的能力(通过join操作)。为了说明KStreams和KTables/ GlobalKTables之间的区别,让我们想想一下两个数据记录发送到流中:
("alice", 1) --> ("alice", 3)
假设流处理应用程序是求总和,如果这个是KStream,它将返回4。如果是KTable或GlobalKTable,将返回的是3,因为最后的记录被认为是一个更新动作。
创建源流
记录流(KStreams)或变更日志流(KTable或GlobalkTable)可以从一个或多个Kafka主题创建源流,(而KTable和GlobalKTable,只能从单个主题创建源流)。
KStreamBuilder builder = new KStreamBuilder();
KStream<String, GenericRecord> source1 = builder.stream("topic1", "topic2");
KTable<String, GenericRecord> source2 = builder.table("topic3", "stateStoreName");
GlobalKTable<String, GenericRecord> source2 = builder.globalTable("topic4", "globalStoreName");
Windowing a stream(窗口流)
流处理器可能需要将数据记录划分为时间段。即,通过时间窗口。通常用于连接和聚合操作等。Kafka Streams当前定义了一下的类型窗口:
跳跃时间窗口是基于时间间隔的窗口。此模式固定大小,(可能)重叠的窗口。通过2个属性来定义跳跃窗口:窗口的大小和其前进间隔(又叫“跳跃”)。前进间隔是根据前一个窗口来指定向前移动多少。例如,你可以配置一个跳跃窗口,大小为5分钟,前进间隔是1分钟。由于跳跃窗口可以重叠。因此数据记录可以属于多于一个这样的窗口。滚动时间窗口是跳跃时间窗口的特殊情况,并且像后者一样,也是基于时间间隔。其模型固定大小,非重叠,无间隔窗口。滚动窗口是通过单个属性来定义的:窗口的大小。滚动窗口等于其前进间隔的跳跃窗口大小。由于滚动窗口不会重叠,数据记录仅属于一个且仅有一个窗口。滑动窗口模式是基于时间轴的连续滑动的固定大小的窗口。如果它们的时间戳的差在窗口大小内,则两个数据记录包含在同一个窗口中。因此,滑动窗口不和epoch对准,而是与数据时间戳对准。在Kafka Streams中,滑动窗口仅用于join操作,并且可通过JoinWindows类指定。会话窗口(Session windows)是基于key事件聚合成会话。会话表示一个活动期间,由不活动间隔分割定义的。在任何现有会话的不活动间隔内处理的任何事件都将合并到现有的会话中。如果事件在会话间隔之外,那么将创建新的会话。会话窗口独立的跟踪的key(即,不同key的窗口通常开始和结束时间不同)和它们大小的变化(即使相同的key的窗口大小通常都不同)。因为这样session窗口不能被预先计算,而是从数据记录的时间戳分析获取的。
在Kafka Streams DLS中,开发者可以指定保留窗口的周期。允许保留旧的窗口段一段时间。为了等待晚到的记录(时间戳落在窗口间隔内的)。如果记录过了保留周期之后到达,则不能处理,并将该其删除。
在实时数据流中,晚到的记录始终是可能的。这取决于如何有效的处理延迟记录。利用处理时间,语义是何时处理数据,这意味着延迟记录的概念不适用这个,因为根据定义,没有记录会晚到。因此,晚到的记录实际上可以被认为是事件时间或咽下时间(ingestion-time)。在这两种情况下,Kafka Streams能正常处理晚到的消息。
Join multiple streams(连接多个流)
join(连接,加入)操作基于其数据记录的key来合并两个流,并产生一个新的流。在记录流上通常需要在窗口的基础上执行连接,否则为了执行连接必须保持记录的数量可以无限增长。在Kafka Streams中,可以执行以下连接操作:
KStream对Kstreams连接始终基于窗口,否则内存和状态需要计算加入的无限增长大小。这里,从流中新接收的记录与指定窗口间隔内的其他流的记录相连接,为每个匹配生成一个结果(基于用户提供的ValueJoiner)。新KStream实例表示从此操作者返回join流的结果。KTable对KTable连接连接操作设计和关系型数据库中连接操作一致。这里,两个变更日志流首先是本地状态存储。当从流中接收新的记录时,它与其他流的状态仓库相结合,为每个匹配对生成一个结果(基于用户提供的ValueJoiner)。新KTable实例表示连接流的结果,它也代表表的变更日志流,从此操作人返回。KStream对KTable连接允许当你从另一个记录流(KStream)接受到新记录时,针对变更日志刘(KTabloe)执行表查询。例如,用最新的用户个人信息(KTable)来填充丰富用户的活动流(KStream)。只有从记录流接受的记录触发连接并通过ValueJoiner生成结果,反之(即,从变更日志流接收的记录将只更新状态仓库)。新的KStream表示该操作者返回的接入结果流。KStream对GlobalKTable连接允许你基于从其他记录流(KStream)接受到新记录时,针对一个完整复制的变更日志流(GlobalKTable)执行表查询。连接GlobalKTable不需要重新分配输入KStream,因为GlobalKTable的所有分区在每个KafkaStreams实例中都可用。与连接操作一起提供的KeyValueMapper应用到每个KStream记录,提取用于查找GlobalKTable的连接key,从而可以进行非记录key连接。例如,用最新的用户个人信息(GlobalKTable)来丰富用户活跃流(KStream)。只有从记录流接收的记录触发连接并产生结果(通过ValueJoiner),反之亦然(即,从变更日志流接收的记录仅被用于更新状态仓库)。新的KStream实例代表从该操作者返回的连接结果流。
根据操作数,支持以下连接操作:内部连接,外部连接和左连接。类似于关系型数据库。
聚合流
聚合操作采用一个输入流,并通过将多个输入记录合并成单个输出记录来产生一个新的流。计算数量或总数的例子,记录流上通常需要在窗口基础上执行聚合,否则为了执行聚合操作必须保持记录数可以无限地增长。
在Kafka Streams DSL中,聚合操作的输入流可以是KStream或KTable,但是输出流将始终是KTable,允许Kafka Streams在生成或发出之后,最后抵达的记录更新聚合的值。当这种晚到到达的记录发生,聚合KStream或KTtable只是发出一个新的聚合值。由于输出是KTable,所以在后续的处理步骤中,具有key的旧值将被新值覆盖。
转换流
除了join(连接)和聚合操作之外,KStream和KTable各自提供其他的转换操作。这些操作每一个都可以生成一个或多个KStream和Ktable对象,并可以转换成一个或多个连接的处理器到底层处理器拓扑中。所有这些转换方法可以链接在一起构成一个复杂的处理器拓扑。由于KSteram和KTable是强类型的,所有转换操作都被定义为泛型,用户可以在其中指定输出和输出数据的类型。
这些转换中,filter,map,myValues等是无状态操作,可应用于KStream和KTable,用户通常可以自定义函数作为参数传递给这些函数,如Predicate的filter,MapValueMapper的map等:
// written in Java 8+, using lambda expressions
KStream<String, GenericRecord> mapped = source1.mapValue(record -> record.get("category"));
无状态转换,不需要处理任何状态。因此在实现上它们不需要流处理器的状态仓库。另一方面,有状态的转换,则需要状态仓库。例如,在连接和聚合操作中,使用窗口状态来存储所有目前为止在定义窗口边界内的所有接收的记录。然后,操作员可以访问这些存储的记录,并基于它们进行计算。
// written in Java 8+, using lambda expressions
KTable<Windowed<String>, Long> counts = source1.groupByKey().aggregate(
() -> 0L, // initial value
(aggKey, value, aggregate) -> aggregate + 1L, // aggregating value
TimeWindows.of("counts", 5000L).advanceBy(1000L), // intervals in milliseconds
Serdes.Long() // serde for aggregated value
);
KStream<String, String> joined = source1.leftJoin(source2,
(record1, record2) -> record1.get("user") + "-" + record2.get("region");
);
将流写回kafka
在处理结束后,开发者可以通过KStream.to和KTable.to将最终的结果流(连续不断的)写回Kafka主题。
joined.to("topic4");
如果已经通过上面的to方法写入到一个主题中,但是如果你还需要继续读取和处理这些消息,可以从输出主题构建一个新流,Kafka Streams提供了一个便利的方法,through:
// equivalent to
//
// joined.to("topic4");
// materialized = builder.stream("topic4");
KStream materialized = joined.through("topic4");
应用程序的配置和执行
除了定义的topology,开发者还将需要在运行它之前在StreamsConfig配置他们的应用程序,Kafka Stream配置的完整列表可以在这里找到。
Kafka Streams中指定配置和生产者、消费者客户端类似,通常,你创建一个java.util.Properties,设置必要的参数,并通过Properties实例构建一个StreamsConfig实例。
import java.util.Properties;
import org.apache.kafka.streams.StreamsConfig;
Properties settings = new Properties();
// Set a few key parameters
settings.put(StreamsConfig.APPLICATION_ID_CONFIG, "my-first-streams-application");
settings.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-broker1:9092");
settings.put(StreamsConfig.ZOOKEEPER_CONNECT_CONFIG, "zookeeper1:2181");
// Any further settings
settings.put(... , ...);
// Create an instance of StreamsConfig from the Properties instance
StreamsConfig config = new StreamsConfig(settings);
除了Kafka Streams自己配置参数,你也可以为Kafka内部的消费者和生产者指定参数。根据你应用的需要。类似于Streams设置,你可以通过StreamsConfig设置任何消费者和/或生产者配置。请注意,一些消费者和生产者配置参数使用相同的参数名。例如,用于配置TCP缓冲的send.buffer.bytes或receive.buffer.bytes。用于控制客户端请求重试的request.timeout.ms和retry.backoff.ms。如果需要为消费者和生产者设置不同的值,可以使用consumer.或producer.作为参数名称的前缀。
Properties settings = new Properties();
// Example of a "normal" setting for Kafka Streams
settings.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-broker-01:9092");
// Customize the Kafka consumer settings
streamsSettings.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 60000);
// Customize a common client setting for both consumer and producer
settings.put(CommonClientConfigs.RETRY_BACKOFF_MS_CONFIG, 100L);
// Customize different values for consumer and producer
settings.put("consumer." + ConsumerConfig.RECEIVE_BUFFER_CONFIG, 1024 * 1024);
settings.put("producer." + ProducerConfig.RECEIVE_BUFFER_CONFIG, 64 * 1024);
// Alternatively, you can use
settings.put(StreamsConfig.consumerPrefix(ConsumerConfig.RECEIVE_BUFFER_CONFIG), 1024 * 1024);
settings.put(StremasConfig.producerConfig(ProducerConfig.RECEIVE_BUFFER_CONFIG), 64 * 1024);
你可以在应用程序代码中的任何地方使用Kafka Streams,常见的是在应用程序的main()方法中使用。
首先,先创建一个KafkaStreams实例,其中构造函数的第一个参数用于定义一个topology builder(Streams DSL的KStreamBuilder,或Processor API的TopologyBuilder)。第二个参数是上面提到的StreamsConfig的实例。
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStreamBuilder;
import org.apache.kafka.streams.processor.TopologyBuilder;
// Use the builders to define the actual processing topology, e.g. to specify
// from which input topics to read, which stream operations (filter, map, etc.)
// should be called, and so on.
KStreamBuilder builder = ...; // when using the Kafka Streams DSL
//
// OR
//
TopologyBuilder builder = ...; // when using the Processor API
// Use the configuration to tell your application where the Kafka cluster is,
// which serializers/deserializers to use by default, to specify security settings,
// and so on.
StreamsConfig config = ...;
KafkaStreams streams = new KafkaStreams(builder, config);
在这点上,内部结果已经初始化,但是处理还没有开始。你必须通过调用start()方法启动kafka Streams线程:
// Start the Kafka Streams instance
streams.start();
捕获任何意外的异常,设置java.lang.Thread.UncaughtExceptionHandler。每当流线程由于意外终止时,将调用此处理程序。
streams.setUncaughtExceptionHandler(new Thread.UncaughtExceptionHandler() {
public uncaughtException(Thread t, throwable e) {
// here you should examine the exception and perform an appropriate action!
}
);
close()方法结束程序。
// Stop the Kafka Streams instance
streams.close();
现在,运行你的应用程序,像其他的Java应用程序一样(Kafka Sterams没有任何特殊的要求)。同样,你也可以打包成jar,通过以下方式运行:
# Start the application in class `com.example.MyStreamsApp`
# from the fat jar named `path-to-app-fatjar.jar`.
$ java -cp path-to-app-fatjar.jar com.example.MyStreamsApp
当应用程序实例开始运行时,定义的处理器拓扑将被初始化成1个或多个流任务,可以由实例内的流线程并行的执行。如果处理器拓扑定义了状态仓库,则这些状态仓库在初始化流任务期间(重新)构建。这一点要理解,当如上所诉的启动你的应用程序时,实际上Kafka Streams认为你发布了一个实例。现实场景中,更常见的是你的应用程序有多个实例并行运行(如,其他的JVM中或别的机器上)。在这种情况下,Kafka Streams会将任务从现有的实例中分配给刚刚启动的新实例。有关详细的信息,请参阅流分区和任务和线程模型。
9.5 升级指南和API变化
如果要从0.10.1.x升级到0.10.2。请参与0.10.2的升级部分。主要强调了升级应用时需要考虑的不兼容性。下面是完整的0.10.2 API和变化列表,提升你的程序或简化代码,并包含了新功能的使用。
0.10.2.0中Streams API的变化
KafkaStreams中的新方法:
- 设置一个监听器来响应程序状态的变化(
#setStateListener(StateListener listener))。 - 通过
#state检查当前应用程序的状态。 - 通过
#metrics()检索全局度量注册 - 通过
close(long timeout,TimeUnit timeUnit)关闭时的超时时间 - 通过
#toString(String indent)检查Kafka Streams信息时指定自定义的缩进
StreamsConfig中的参数的变化:
zookeeper.connect已废弃;Kafka Streams应用程序的topic管理不在与Zookeeper相互影响,而是使用新的broker管理协议(参见KIP-4,"主题管理模式"一节)- 为度量,安全和客户端配置增加了许多新参数
StreamsMetrics接口中的变化
- 移除方法:
#addLatencySensor() - 增加方法:
#addLatencyAndThroughputSensor(),#addThroughputSensor(),#recordThroughput(),#addSensor(),#removeSensor()
TopologyBuilder中的新方法:
- 增加了
#addSource()的重载,允许为每个源节点定义一个auto.offset.reset策略 - 增加了
#addGlobalStore()方法,添加到全局StateStores
KStreamBuilder中的新方法:
- 增加了
#stream()和#table()的重载。允许为每个输入stream/table定义一个auto.offset.reset策略。
added method #globalKTable() to create a GlobalKTable - 添加方法
#globalKTable()来创建GlobalKTable
KStream的新连接
- 增加了用于和KTable连接的
#join()重载。 - 增加了用于和GlobalKTable连接的
#join和leftJoin()重载。 - 注意,0.10.2中的
连接有所改进,因此你需要与0.10.0.x和0.10.1.x进行对比,可能会看到不同的结果(参见Apache Kafka wiki中的Kafka Streams Join语义)
KTable连接的空键对其处理
- 像其他的KTable操作一样,
KTable-KTable连接不再对空键抛出异常,而是静静的删除这些记录。
新增窗口类型会话窗口
- 添加了SessionWindows类来指定会话窗口
- 增加了KGroupedStream方法的重载:
#count(),#reduce()和#aggregate(),以允许会话窗口聚合。
TimestampExtractor的变化:
#extract()方法增加了第二个参数- 新的默认时间戳提取器类
FailOnInvalidTimestamp(提供了与旧的(和已经移除的)默认提取器ConsumerRecordTimestampExtractor相同的功能) - 新替代时间戳提取器类
LogAndSkipOnInvalidTimestamp和UsePreviousTimeOnInvalidTimestamps.
许多DSL接口、类和方法的松散类型约束(参见.KIO-100)。
Streams API更改为0.10.1.0
流分组和聚合分为2个方法:
- 老的: KStream #aggregateByKey(), #reduceByKey(), #countByKey()
- 新的: KStream#groupByKey() plus KGroupedStream #aggregate(), #reduce(), 和 #count()
- 例子: stream.countByKey() 更改为 stream.groupByKey().count()
自动重新分配:
- 在变更密钥操作之后和aggregation/join之前,不需要调用through()
- 例子:stream.selectKey(...).through(...).countByKey() 变更为 stream.selectKey().groupByKey().count()
TopologyBuilder:
#sourceTopics(String applicationId)and#topicGroups(String applicationId)方法简化为#sourceTopics()和#topicGroups()
DSL: 指向状态仓库名的新参数:
- 新的Interactive Queries功能需要为所有源KTables和窗口聚合结果KTables指定一个存储名称(之前的参数“operator/window name”现在是storeName)
- KStreamBuilder#table(String topic) 变更为 #topic(String topic, String storeName)
- KTable#through(String topic) 变更为 #through(String topic, String storeName)
- KGroupedStream #aggregate(), #reduce(), 和 #count() 需要增加额外的参数 "String storeName"
例子: stream.countByKey(TimeWindows.of("windowName", 1000)) 变更为 stream.groupByKey().count(TimeWindows.of(1000), "countStoreName")
窗口:
- Windows不再命名: TimeWindows.of("name", 1000) 变更为 TimeWindows.of(1000) (参见DSL:新参数指定状态仓库的名称)
- JoinWindows没有默认的大小: JoinWindows.of("name").within(1000) 变更为 to JoinWindows.of(1000)



你好,官网上https://kafka.apache.org/32/documentation/streams/developer-guide/dsl-api.html#joining 对Left (KStream) Right (KStream)各种join的表格例子,里面随着timestamp + +,而产生的join结果,应该是增量吧?即到window time out时,产出的结果应该是整个一纵列的结果合集。不知道理解的对不对,望指点。
我自己想试着在本地运行一下看看,但是小白一个,还没跑起来。
join的结果是一纵列的合集。
实践是检验的唯一真理
博主好,请问我在应用启动后,在某些时候动态的构建了不同的kafka stream并启动,是否等同于我启动了多个stream客户端
虽然我不知道你怎么实现的,但如果是new就是。
确实是new,因为我无法在我应用启动前确定需要构建的stream定义,因为是第一次有这样的场景,所以不知道这样的情况是否还适合用kafka streams
有四个用户,他们的用户足迹如下:A、B、A、C、A、D,如果想聚合每个用户的防护次数很简单:A3 B1 C1 D1。但如果想算总用户量即 count(distinct user_id) ,这个用streams该怎么算呢?
或者用sql的: select count(1) from (select count(1) group by user_id)嵌套一下。
统计出现的次数,这个不是经典案例吗。。
kafka streams能做到输入2个topic的数据,通过某种关系,将两个topic的数据输出到1个topic中吗
可以,addProcessor可以传多个,你关注下这个方法。
Kafka Streams的统计只能适用于一个字段的累积个数吗?对于类似于多个字段group by 甚至加上条件,获取个别字段,这种情况满足吗?类似于s q l :select a,b,c where d=11 group by e,f,g
用Kafka Streams创建的应用能处理一个topic的其中一个分区在某一个时间点以后的数据吗?还是每次创建的应用必须从topic的一个分区的头开始处理
没的,Kafka Streams的设计初衷不是用于你这种情况。
你好,也就是说Kafka Streams不能指定时间戳查询数据,对吧
嗯,消费者类封装进去了,没提供出口。
你好,请问kstreams中的一条数据可以模糊匹配join多条globalktable中的数据吗,我想最后结果是Join得到多条结果
可以
想问下 Kafka Streams的 应用场景?没搞懂 和 Connector区别是什么?
connector是传输。
streams流式计算:跟小溪流向大海一样,一层一层的加工,最终流到大海的是一个加工后的全新数据。
比如,统计、告警、分发、对账等
@半兽人:
在做stream计算的时候,起了多个消费者,那各个节点的统计结果,怎么做的数据合并的?
KeyValueStore<String, String> kvStore;这个有具体的资料吗,我看网上介绍这个的好少。
请问我想要实现以下功能:对于一个分区来说,采集出来的数据被多个线程并行的写入到mysql中。这个需要如何实现呢?
类似于我用kafka consumer从topic的分区中采集出了一批数据,这批数据我需要启5个线程向mysql中并行的插入数据。这样的需求使用kafka
stream 会不会得到解决呢?
可以解决。逻辑层你自己写,注意线程work会启动多个,注意线程安全。
您好:
请问kafka streams 在多进程的情况写可以保证消息的有序性么?多进程的streams源都是同一个Topic
不行的,除非1个分区,1个work。
1个分区就不可以多个streams并发了,并发就不能保证有序性了么?
消息在分区中是有序的,但是多个消费者在拿消息的时候,快慢就没办法保证了。
针对一个kafka stream主题 (topic),创建一个处理集群(属于同一个group,多机环境部署同一套代码),是否认为kafka的机制保证了数据最后,可以被正确的聚合处理到一起?
例如,我要检测环境数据,当环境数据超过某个界限,发出警告。使用多机部署的方式,是否能够保证多机处理结果被正确融合?