一个小应用程序来监视kafka消费者的进度和它们的延迟的队列。
KafkaOffsetMonitor是用来实时监控Kafka集群中的consumer以及在队列中的位置(偏移量)。
你可以查看当前的消费者组,每个topic队列的所有partition的消费情况。可以很快地知道每个partition中的消息是否很快被消费以及相应的队列消息增长速度等信息。这些可以debug kafka的producer和consumer,你完全知道你的系统将会发生什么。
这个web管理平台保留的partition offset和consumer滞后的历史数据(具体数据保存多少天我们可以在启动的时候配置),所以你可以很轻易了解这几天consumer消费情况。
KafkaOffsetMonitor这款软件是用Scala代码编写的,消息等历史数据是保存在名为offsetapp.db数据库文件中,该数据库是SQLLite文件,非常的轻量级。虽然我们可以在启动KafkaOffsetMonitor程序的时候指定数据更新的频率和数据保存的时间,但是不建议更新很频繁,或者保存大量的数据,因为在KafkaOffsetMonitor图形展示的时候会出现图像展示过慢,或者是直接导致内存溢出了。
所有的关于消息的偏移量、kafka集群的数量等信息都是从Zookeeper中获取到的,日志大小是通过计算得到的。
消费者组列表
消费组的topic列表
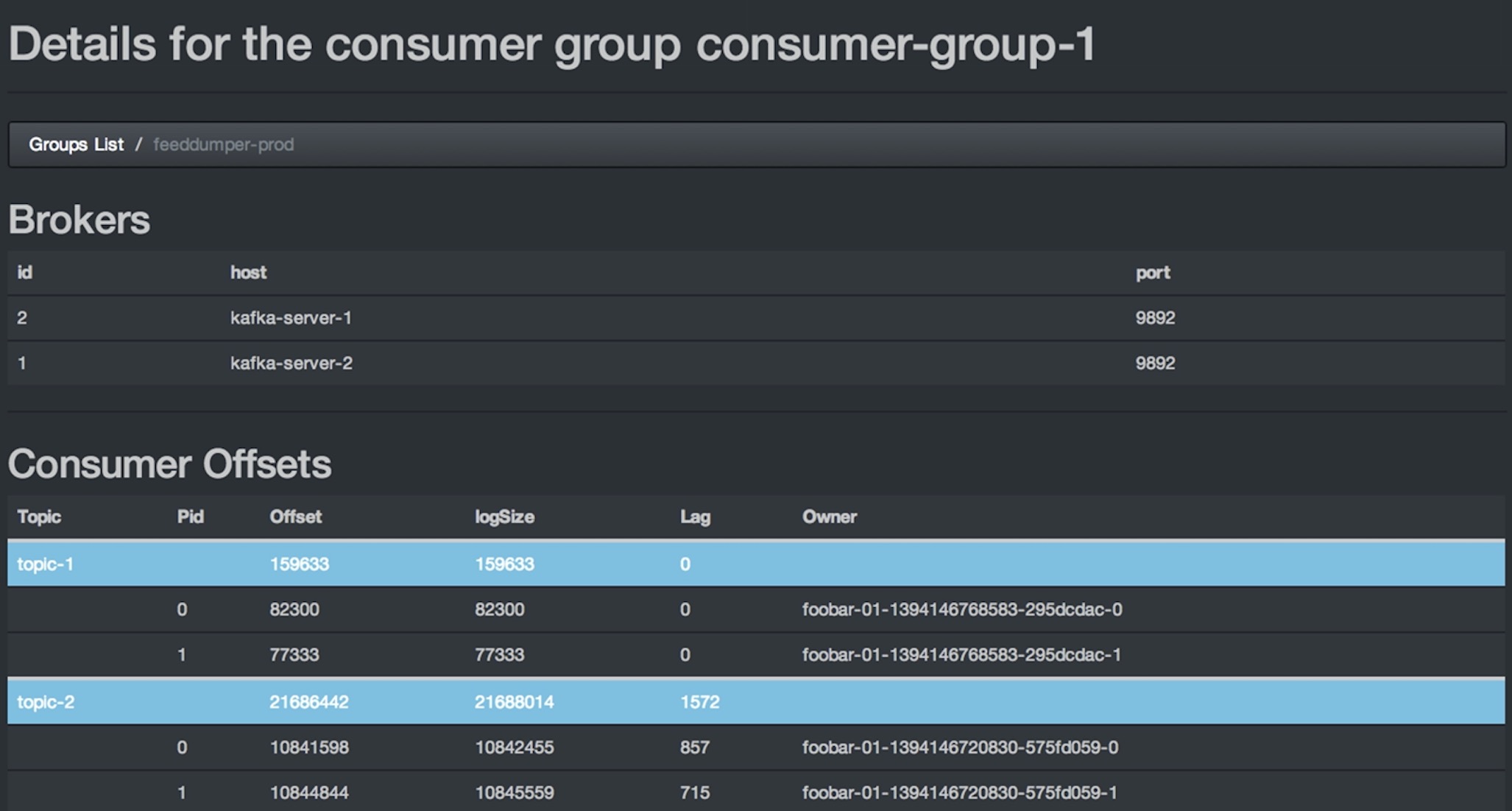
图中参数含义解释如下:
- topic:创建时topic名称
- partition:分区编号
- offset:表示该parition已经消费了多少条message
- logSize:表示该partition已经写了多少条message
- Lag:表示有多少条message没有被消费。
- Owner:表示消费者
- Created:该partition创建时间
- Last Seen:消费状态刷新最新时间。
topic的历史位置
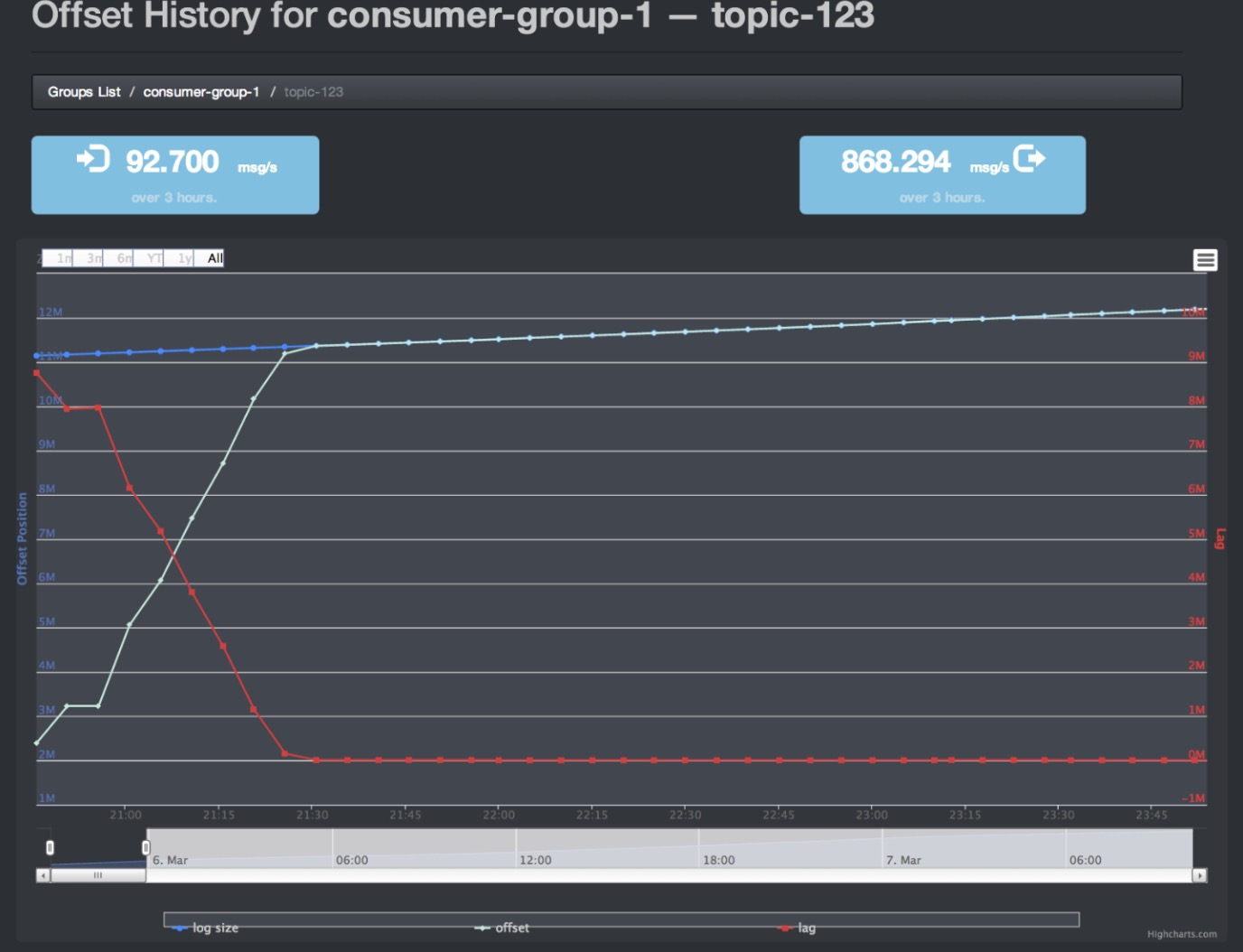
Offset存储位置
kafka能灵活地管理offset,可以选择任意存储和格式来保存offset。KafkaOffsetMonitor目前支持以下流行的存储格式。
- kafka0.8版本以前,offset默认存储在zookeeper中(基于Zookeeper)
- kafka0.9版本以后,offset默认存储在内部的topic中(基于Kafka内部的topic)
- Storm Kafka Spout(默认情况下基于Zookeeper)
KafkaOffsetMonitor每个运行的实例只能支持单一类型的存储格式。
下载
可以到github下载KafkaOffsetMonitor源码。
https://github.com/quantifind/KafkaOffsetMonitor
编译KafkaOffsetMonitor命令:
sbt/sbt assembly
不过不建议你自己去下载,因为编译的jar包里引入的都是外部的css和js,所以打开必须联网,都是国外的地址,你编译的时候还要修改js路径,我已经搞定了,你直接下载就好了。
百度云盘:https://pan.baidu.com/s/1kUZJrCV
启动
编译完之后,将会在KafkaOffsetMonitor根目录下生成一个类似KafkaOffsetMonitor-assembly-0.3.0-SNAPSHOT.jar的jar文件。这个文件包含了所有的依赖,我们可以直接启动它:
java -cp KafkaOffsetMonitor-assembly-0.3.0-SNAPSHOT.jar \
com.quantifind.kafka.offsetapp.OffsetGetterWeb \
--offsetStorage kafka \
--zk zk-server1,zk-server2 \
--port 8080 \
--refresh 10.seconds \
--retain 2.days
启动方式2,创建脚本,因为您可能不是一个kafka集群。用脚本可以启动多个。
vim mobile_start_en.sh
nohup java -Xms512M -Xmx512M -Xss1024K -XX:PermSize=256m -XX:MaxPermSize=512m -cp KafkaOffsetMonitor-assembly-0.3.0-SNAPSHOT.jar com.quantifind.kafka.offsetapp.OffsetGetterWeb
--offsetStorage kafka
--zk 127.0.0.1:2181
--port 8080
--refresh 10.seconds
--retain 2.days 1>mobile-logs/stdout.log 2>mobile-logs/stderr.log &
各个参数的含义:
- offsetStorage:有效的选项是"zookeeper","kafka","storm"。0.9版本以后,offset存储的位置在kafka。
- zk: zookeeper的地址
- prot 端口号
- refresh 刷新频率,更新到DB。
- retain 保留DB的时间
- dbName 在哪里存储记录(默认'offsetapp')



使用0.4.6版本和2.6.2版本Kafka,报错信息:
ERROR KafkaOffsetGetter$:103 - The message was malformed and does not conform to a type of (BaseKey, OffsetAndMetadata. Ignoring this message. kafka.common.KafkaException: Unknown offset schema version 3 at kafka.coordinator.GroupMetadataManager$.schemaForOffset(GroupMetadataManager.scala:739) at kafka.coordinator.GroupMetadataManager$.readOffsetMessageValue(GroupMetadataManager.scala:884) at com.quantifind.kafka.core.KafkaOffsetGetter$.tryParseOffsetMessage(KafkaOffsetGetter.scala:277) at com.quantifind.kafka.core.KafkaOffsetGetter$.startCommittedOffsetListener(KafkaOffsetGetter.scala:351) at com.quantifind.kafka.OffsetGetter$$anon$3.run(OffsetGetter.scala:289) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745)您好,博主,我按照您的方法,部署上了,不加--offsetStorage kafka 会正常启动,但是里面显示Unable to find Active Consumers,而且消费群组也是不正确的。输出的日志如下:
[root@slave01 ~]# java -cp KafkaOffsetMonitor-assembly-0.3.0-SNAPSHOT.jar com.quantifind.kafka.offsetapp.OffsetGetterWeb --zk 10.110.86.59:2181,10.110.83.150:2181,10.110.83.151:2181 --port 8089 --refresh 5.seconds --retain 5.days serving resources from: jar:file:/root/KafkaOffsetMonitor-assembly-0.3.0-SNAPSHOT.jar!/offsetapp 2020-10-13 14:47:47 INFO Server:272 - jetty-8.y.z-SNAPSHOT 2020-10-13 14:47:47 INFO ZkEventThread:64 - Starting ZkClient event thread. 2020-10-13 14:47:47 INFO ZooKeeper:100 - Client environment:zookeeper.version=3.4.6-1569965, built on 02/20/2014 09:09 GMT 2020-10-13 14:47:47 INFO ZooKeeper:100 - Client environment:host.name=slave01 2020-10-13 14:47:47 INFO ZooKeeper:100 - Client environment:java.version=1.8.0_181 2020-10-13 14:47:47 INFO ZooKeeper:100 - Client environment:java.vendor=Oracle Corporation 2020-10-13 14:47:47 INFO ZooKeeper:100 - Client environment:java.home=/usr/java/jdk1.8.0_181-cloudera/jre 2020-10-13 14:47:47 INFO ZooKeeper:100 - Client environment:java.class.path=KafkaOffsetMonitor-assembly-0.3.0-SNAPSHOT.jar 2020-10-13 14:47:47 INFO ZooKeeper:100 - Client environment:java.library.path=/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib 2020-10-13 14:47:47 INFO ZooKeeper:100 - Client environment:java.io.tmpdir=/tmp 2020-10-13 14:47:47 INFO ZooKeeper:100 - Client environment:java.compiler=2020-10-13 14:47:47 INFO ZooKeeper:100 - Client environment:os.name=Linux 2020-10-13 14:47:47 INFO ZooKeeper:100 - Client environment:os.arch=amd64 2020-10-13 14:47:47 INFO ZooKeeper:100 - Client environment:os.version=3.10.0-1127.19.1.el7.x86_64 2020-10-13 14:47:47 INFO ZooKeeper:100 - Client environment:user.name=root 2020-10-13 14:47:47 INFO ZooKeeper:100 - Client environment:user.home=/root 2020-10-13 14:47:47 INFO ZooKeeper:100 - Client environment:user.dir=/root 2020-10-13 14:47:47 INFO ZooKeeper:438 - Initiating client connection, connectString=master:2181,slave01:2181,slave02:2181 sessionTimeout=30000 watcher=org.I0Itec.zkclient.ZkClient@28af6e40 2020-10-13 14:47:47 INFO AbstractConnector:338 - Started SocketConnector@0.0.0.0:8089 2020-10-13 14:47:47 INFO ClientCnxn:975 - Opening socket connection to server slave02/slave02:2181. Will not attempt to authenticate using SASL (unknown error) 2020-10-13 14:47:47 INFO ClientCnxn:852 - Socket connection established to slave02/slave02:2181, initiating session 2020-10-13 14:47:47 INFO ClientCnxn:1235 - Session establishment complete on server slave02/slave02:2181, sessionid = 0x274b9ffdd77b9fa, negotiated timeout = 30000 2020-10-13 14:47:47 INFO ZkClient:449 - zookeeper state changed (SyncConnected) 2020-10-13 14:47:47 INFO OffsetGetterWeb$:68 - reporting 0 2020-10-13 14:47:47 INFO OffsetGetterWeb$:68 - reporting 0 2020-10-13 14:47:47 INFO OffsetGetterWeb$:68 - reporting 0 2020-10-13 14:47:47 INFO OffsetGetterWeb$:68 - reporting 0你启动完监控之后,你启动一下消费者和生产者,看看是否有数据了。
博主,还是没有数据,无论是在命令行启动消费者还是生产者,在消费群组中还是只有没有用的groupid,能显示出topic列表,但是点开后出现Unable to find Active Consumers。
消费者能消费到消息吗
可以的博主,我感觉是因为没有连接到zookepper呢,输出日志有一条:
2020-10-13 14:47:47 INFO ClientCnxn:975 - Opening socket connection to server slave02/slave02:2181. Will not attempt to authenticate using SASL (unknown error) 2020-10-13 14:47:47 INFO ClientCnxn:852 - Socket connection established to slave02/slave02:2181, initiating session您看是不是这里的原因
消费群组中是:
ggg KafkaOffsetMonitor-1602557247862 group KafkaOffsetMonitor-1602554782142我记得没有创建过这些消费者群组。
这些组你看名字,有个是kafka监控的,其他的肯定有其他在用的,或者是之前的,只是你不知道。
如果你需要验证,清理一个干净集群后,在看看,或者直接用kafka命令查看。
https://www.orchome.com/454
博主您好,我用kafka查看所有的消费者列表,并没有在KafkaOffsetMonitor显示的消费群组,命令行展示的消费群组:
test
cons1
foo
myGroup
我使用的命令是:./kafka-consumer-groups.sh --zk master:9092 --list
注意你的offset存储在哪里。
您好博主,我看了一下,offset存储到了kafka自带的topic下。在zookepper中的comsumer文件夹里存在的就是KafkaOffsetMonitor那四个的消费群组。如果而我在命令中添加了--offsetStorage kafka 就会报错,
2020-10-14 08:44:47 WARN KafkaOffsetGetter$:89 - Failed to process one of the commit message due to exception. The 'bad' message will be skipped java.lang.RuntimeException: Unknown offset schema version 3 at com.quantifind.kafka.core.KafkaOffsetGetter$.schemaFor(KafkaOffsetGetter.scala:162) at com.quantifind.kafka.core.KafkaOffsetGetter$.readMessageValueStruct(KafkaOffsetGetter.scala:234) at com.quantifind.kafka.core.KafkaOffsetGetter$.com$quantifind$kafka$core$KafkaOffsetGetter$$readMessageValue(KafkaOffsetGetter.scala:204) at com.quantifind.kafka.core.KafkaOffsetGetter$$anonfun$startOffsetListener$1.apply$mcV$sp(KafkaOffsetGetter.scala:101) at com.quantifind.kafka.core.KafkaOffsetGetter$$anonfun$startOffsetListener$1.apply(KafkaOffsetGetter.scala:87) at com.quantifind.kafka.core.KafkaOffsetGetter$$anonfun$startOffsetListener$1.apply(KafkaOffsetGetter.scala:87) at scala.concurrent.impl.Future$PromiseCompletingRunnable.liftedTree1$1(Future.scala:24) at scala.concurrent.impl.Future$PromiseCompletingRunnable.run(Future.scala:24) at scala.concurrent.impl.ExecutionContextImpl$$anon$3.exec(ExecutionContextImpl.scala:107) at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260) at scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339) at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979) at scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)你kafka是什么版本。报的是版本兼容问题。
我用的是CDH6.3.2版的kafka2.2.1。我去选择了另一个监测的工具kafka Eagle,博主您感觉这个工具在实际生产环境用靠谱不?
可以,kafka-manager不是给运维用的,是给开发人员check用的。
好几年不维护了,我本来想维护,奈何事情太多。
博主威武,想偶像大佬学习。
博主,我还请教一下,kafka 的主题分区时创建时就确定的,而且不能更改,为了保证数据不会出现拥堵现象,应该如何确定分区的个数呢?
topic的分区数 <= 节点数 *2 (分区数相当于队列数,你将消息分别放到这些队列里,你的消费者可以并行处理的数量)
准确的来说,压力一般来自于消费者消费不过来,这个时候你可以增加消费者来提高并行处理(消费者数量<=分区数)。
ps:有问题到问题专区提吧。
谢谢博主,可以用吞吐量指标来设计分区的大小吗,比如说,生产者每秒生产100M的数据,需要进行多少的分区
不用,就按照上面的标准就行了。
性能是整个集群的,如果你一台物理机就300M,那你怎么分都不行。
java -cp KafkaOffsetMonitor-assembly-0.2.0.jar com.quantifind.kafka.offsetapp.OffsetGetterWeb --offsetStorage kafka --zk 192.168.64.44:2183 --port 8088 --refrh 10.seconds --retain 2.days Exception in thread "main" com.quantifind.sumac.ArgException: unknown option offsetStorage不加--offsetStorage kafka 会正常启动,但是里面显示Unable to find Active Consumers
只是提示你没有找到活跃的消费者而已。
但是有消费者在消费的呀
你kafka什么版本?
offsetStorage:有效的选项是"zookeeper","kafka","storm"。0.9版本以后,offset存储的位置在kafka。
# find ./libs/ -name \*kafka_\* | head -1 | grep -o '\kafka[^\n]*' kafka_2.12-2.3.0-sources.jar.asc解决了吗?
请问一下,您解决了吗
您好 我也遇到了 这个问题 请问解决了吗
我在操作消费kafka队列时出现 numRecords must not be negative 该如何解决?
java.lang.IllegalArgumentException: requirement failed: numRecords must not be negative at scala.Predef$.require(Predef.scala:233) at org.apache.spark.streaming.scheduler.StreamInputInfo.(InputInfoTracker.scala:38) at org.apache.spark.streaming.kafka.DirectKafkaInputDStream.compute(DirectKafkaInputDStream.scala:165) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:351) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:351) at scala.util.DynamicVariable.withValue(DynamicVariable.scala:57) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1.apply(DStream.scala:350) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1.apply(DStream.scala:350) at org.apache.spark.streaming.dstream.DStream.createRDDWithLocalProperties(DStream.scala:425) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1.apply(DStream.scala:345) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1.apply(DStream.scala:343) at scala.Option.orElse(Option.scala:257) at org.apache.spark.streaming.dstream.DStream.getOrCompute(DStream.scala:340) at org.apache.spark.streaming.dstream.MappedDStream.compute(MappedDStream.scala:35) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:351) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:351) at scala.util.DynamicVariable.withValue(DynamicVariable.scala:57) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1.apply(DStream.scala:350) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1.apply(DStream.scala:350) at org.apache.spark.streaming.dstream.DStream.createRDDWithLocalProperties(DStream.scala:425) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1.apply(DStream.scala:345) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1.apply(DStream.scala:343) at scala.Option.orElse(Option.scala:257) at org.apache.spark.streaming.dstream.DStream.getOrCompute(DStream.scala:340) at org.apache.spark.streaming.dstream.MappedDStream.compute(MappedDStream.scala:35) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:351) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:351) at scala.util.DynamicVariable.withValue(DynamicVariable.scala:57) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1.apply(DStream.scala:350) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1.apply(DStream.scala:350) at org.apache.spark.streaming.dstream.DStream.createRDDWithLocalProperties(DStream.scala:425) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1.apply(DStream.scala:345) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1.apply(DStream.scala:343) at scala.Option.orElse(Option.scala:257) at org.apache.spark.streaming.dstream.DStream.getOrCompute(DStream.scala:340) at org.apache.spark.streaming.dstream.FilteredDStream.compute(FilteredDStream.scala:35) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:351) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:351) at scala.util.DynamicVariable.withValue(DynamicVariable.scala:57) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1.apply(DStream.scala:350) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1.apply(DStream.scala:350) at org.apache.spark.streaming.dstream.DStream.createRDDWithLocalProperties(DStream.scala:425) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1.apply(DStream.scala:345) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1.apply(DStream.scala:343) at scala.Option.orElse(Option.scala:257) at org.apache.spark.streaming.dstream.DStream.getOrCompute(DStream.scala:340) at org.apache.spark.streaming.dstream.DStream$$anonfun$slice$2$$anonfun$apply$29.apply(DStream.scala:934) at org.apache.spark.streaming.dstream.DStream$$anonfun$slice$2$$anonfun$apply$29.apply(DStream.scala:933) at scala.collection.TraversableLike$$anonfun$flatMap$1.apply(TraversableLike.scala:251) at scala.collection.TraversableLike$$anonfun$flatMap$1.apply(TraversableLike.scala:251) at scala.collection.Iterator$class.foreach(Iterator.scala:727) at scala.collection.AbstractIterator.foreach(Iterator.scala:1157) at scala.collection.IterableLike$class.foreach(IterableLike.scala:72) at scala.collection.AbstractIterable.foreach(Iterable.scala:54) at scala.collection.TraversableLike$class.flatMap(TraversableLike.scala:251) at scala.collection.AbstractTraversable.flatMap(Traversable.scala:105) at org.apache.spark.streaming.dstream.DStream$$anonfun$slice$2.apply(DStream.scala:933) at org.apache.spark.streaming.dstream.DStream$$anonfun$slice$2.apply(DStream.scala:909) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:150) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:111) at org.apache.spark.SparkContext.withScope(SparkContext.scala:716) at org.apache.spark.streaming.StreamingContext.withScope(StreamingContext.scala:260) at org.apache.spark.streaming.dstream.DStream.slice(DStream.scala:909) at org.apache.spark.streaming.dstream.DStream$$anonfun$slice$1.apply(DStream.scala:903) at org.apache.spark.streaming.dstream.DStream$$anonfun$slice$1.apply(DStream.scala:903) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:150) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:111) at org.apache.spark.SparkContext.withScope(SparkContext.scala:716) at org.apache.spark.streaming.StreamingContext.withScope(StreamingContext.scala:260) at org.apache.spark.streaming.dstream.DStream.slice(DStream.scala:902) at org.apache.spark.streaming.dstream.WindowedDStream.compute(WindowedDStream.scala:65) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:351) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:351) at scala.util.DynamicVariable.withValue(DynamicVariable.scala:57) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1.apply(DStream.scala:350) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1.apply(DStream.scala:350) at org.apache.spark.streaming.dstream.DStream.createRDDWithLocalProperties(DStream.scala:425) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1.apply(DStream.scala:345) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1.apply(DStream.scala:343) at scala.Option.orElse(Option.scala:257) at org.apache.spark.streaming.dstream.DStream.getOrCompute(DStream.scala:340) at org.apache.spark.streaming.dstream.UnionDStream$$anonfun$compute$1.apply(UnionDStream.scala:43) at org.apache.spark.streaming.dstream.UnionDStream$$anonfun$compute$1.apply(UnionDStream.scala:43) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244) at scala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33) at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:108) at scala.collection.TraversableLike$class.map(TraversableLike.scala:244) at scala.collection.mutable.ArrayOps$ofRef.map(ArrayOps.scala:108) at org.apache.spark.streaming.dstream.UnionDStream.compute(UnionDStream.scala:43) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:351) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:351) at scala.util.DynamicVariable.withValue(DynamicVariable.scala:57) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1.apply(DStream.scala:350) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1.apply(DStream.scala:350) at org.apache.spark.streaming.dstream.DStream.createRDDWithLocalProperties(DStream.scala:425) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1.apply(DStream.scala:345) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1.apply(DStream.scala:343) at scala.Option.orElse(Option.scala:257) at org.apache.spark.streaming.dstream.DStream.getOrCompute(DStream.scala:340) at org.apache.spark.streaming.dstream.TransformedDStream$$anonfun$6.apply(TransformedDStream.scala:42) at org.apache.spark.streaming.dstream.TransformedDStream$$anonfun$6.apply(TransformedDStream.scala:42) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244) at scala.collection.immutable.List.foreach(List.scala:318) at scala.collection.TraversableLike$class.map(TraversableLike.scala:244) at scala.collection.AbstractTraversable.map(Traversable.scala:105) at org.apache.spark.streaming.dstream.TransformedDStream.compute(TransformedDStream.scala:42) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:351) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:351) at scala.util.DynamicVariable.withValue(DynamicVariable.scala:57) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1.apply(DStream.scala:350) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1.apply(DStream.scala:350) at org.apache.spark.streaming.dstream.DStream.createRDDWithLocalProperties(DStream.scala:425) at org.apache.spark.streaming.dstream.TransformedDStream.createRDDWithLocalProperties(TransformedDStream.scala:65) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1.apply(DStream.scala:345) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1.apply(DStream.scala:343) at scala.Option.orElse(Option.scala:257) at org.apache.spark.streaming.dstream.DStream.getOrCompute(DStream.scala:340) at org.apache.spark.streaming.dstream.MappedDStream.compute(MappedDStream.scala:35) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:351) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:351) at scala.util.DynamicVariable.withValue(DynamicVariable.scala:57) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1.apply(DStream.scala:350) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1.apply(DStream.scala:350) at org.apache.spark.streaming.dstream.DStream.createRDDWithLocalProperties(DStream.scala:425) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1.apply(DStream.scala:345) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1.apply(DStream.scala:343) at scala.Option.orElse(Option.scala:257) at org.apache.spark.streaming.dstream.DStream.getOrCompute(DStream.scala:340) at org.apache.spark.streaming.dstream.TransformedDStream$$anonfun$6.apply(TransformedDStream.scala:42) at org.apache.spark.streaming.dstream.TransformedDStream$$anonfun$6.apply(TransformedDStream.scala:42) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244) at scala.collection.immutable.List.foreach(List.scala:318) at scala.collection.TraversableLike$class.map(TraversableLike.scala:244) at scala.collection.AbstractTraversable.map(Traversable.scala:105) at org.apache.spark.streaming.dstream.TransformedDStream.compute(TransformedDStream.scala:42) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:351) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:351) at scala.util.DynamicVariable.withValue(DynamicVariable.scala:57) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1.apply(DStream.scala:350) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1.apply(DStream.scala:350) at org.apache.spark.streaming.dstream.DStream.createRDDWithLocalProperties(DStream.scala:425) at org.apache.spark.streaming.dstream.TransformedDStream.createRDDWithLocalProperties(TransformedDStream.scala:65) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1.apply(DStream.scala:345) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1.apply(DStream.scala:343) at scala.Option.orElse(Option.scala:257) at org.apache.spark.streaming.dstream.DStream.getOrCompute(DStream.scala:340) at org.apache.spark.streaming.dstream.ShuffledDStream.compute(ShuffledDStream.scala:41) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:351) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:351) at scala.util.DynamicVariable.withValue(DynamicVariable.scala:57) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1.apply(DStream.scala:350) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1.apply(DStream.scala:350) at org.apache.spark.streaming.dstream.DStream.createRDDWithLocalProperties(DStream.scala:425) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1.apply(DStream.scala:345) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1.apply(DStream.scala:343) at scala.Option.orElse(Option.scala:257) at org.apache.spark.streaming.dstream.DStream.getOrCompute(DStream.scala:340) at org.apache.spark.streaming.dstream.MappedDStream.compute(MappedDStream.scala:35) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:351) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:351) at scala.util.DynamicVariable.withValue(DynamicVariable.scala:57) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1.apply(DStream.scala:350) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1.apply(DStream.scala:350) at org.apache.spark.streaming.dstream.DStream.createRDDWithLocalProperties(DStream.scala:425) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1.apply(DStream.scala:345) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1.apply(DStream.scala:343) at scala.Option.orElse(Option.scala:257) at org.apache.spark.streaming.dstream.DStream.getOrCompute(DStream.scala:340) at org.apache.spark.streaming.dstream.ForEachDStream.generateJob(ForEachDStream.scala:47) at org.apache.spark.streaming.DStreamGraph$$anonfun$1.apply(DStreamGraph.scala:115) at org.apache.spark.streaming.DStreamGraph$$anonfun$1.apply(DStreamGraph.scala:114) at scala.collection.TraversableLike$$anonfun$flatMap$1.apply(TraversableLike.scala:251) at scala.collection.TraversableLike$$anonfun$flatMap$1.apply(TraversableLike.scala:251) at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59) at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47) at scala.collection.TraversableLike$class.flatMap(TraversableLike.scala:251) at scala.collection.AbstractTraversable.flatMap(Traversable.scala:105) at org.apache.spark.streaming.DStreamGraph.generateJobs(DStreamGraph.scala:114) at org.apache.spark.streaming.scheduler.JobGenerator$$anonfun$3.apply(JobGenerator.scala:248) at org.apache.spark.streaming.scheduler.JobGenerator$$anonfun$3.apply(JobGenerator.scala:246) at scala.util.Try$.apply(Try.scala:161) at org.apache.spark.streaming.scheduler.JobGenerator.generateJobs(JobGenerator.scala:246) at org.apache.spark.streaming.scheduler.JobGenerator.org$apache$spark$streaming$scheduler$JobGenerator$$processEvent(JobGenerator.scala:181) at org.apache.spark.streaming.scheduler.JobGenerator$$anon$1.onReceive(JobGenerator.scala:87) at org.apache.spark.streaming.scheduler.JobGenerator$$anon$1.onReceive(JobGenerator.scala:86) at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:48) 20/01/02 11:17:02 ERROR ApplicationMaster: User class threw exception: java.lang.IllegalArgumentException: requirement failed: numRecords must not be negative我也遇到了这个问题 你找到原因了么
1、我用的kafka自带的zookeeper,大概过了一天,zookeeper进程就停掉了。找不到原因,烦请解答。
2、kafka开启了SASL和ACL认证,我在执行监控jar包前:export了环境变量:
-Djava.security.auth.login.config=/home/hadoop/kafka/kafka_2.11-1.0.1/config/kafka_client_jaas.conf现在报错:
2019-12-24 14:50:45 INFO ConsumerFetcherManager:68 - [ConsumerFetcherManager-1577170211362] Added fetcher for partitions ArrayBuffer() ^C2019-12-24 14:50:46 INFO ContextHandler:843 - stopped o.e.j.s.ServletContextHandler{/,jar:file:/home/hadoop/kafka/KafkaOffsetMonitor-assembly-0.3.0-SNAPSHOT.jar!/offsetapp} 2019-12-24 14:50:46 WARN ConsumerFetcherManager$LeaderFinderThread:89 - [KafkaOffsetMonitor-1577170211257_UIP-01-1577170211345-170696dd-leader-finder-thread], Failed to find leader for Set([__consumer_offsets,16], [__consumer_offsets,2], [__consumer_offsets,39], [__consumer_offsets,15], [__consumer_offsets,33], [__consumer_offsets,38], [__consumer_offsets,9], [__consumer_offsets,7], [__consumer_offsets,31], [__consumer_offsets,48], [__consumer_offsets,24], [__consumer_offsets,19], [__consumer_offsets,11], [__consumer_offsets,22], [__consumer_offsets,26], [__consumer_offsets,17], [__consumer_offsets,10], [__consumer_offsets,35], [__consumer_offsets,36], [__consumer_offsets,34], [__consumer_offsets,49], [__consumer_offsets,44], [__consumer_offsets,23], [__consumer_offsets,40], [__consumer_offsets,47], [__consumer_offsets,45], [__consumer_offsets,43], [__consumer_offsets,46], [__consumer_offsets,37], [__consumer_offsets,28], [__consumer_offsets,27], [__consumer_offsets,25], [__consumer_offsets,6], [__consumer_offsets,5], [__consumer_offsets,3], [__consumer_offsets,18], [__consumer_offsets,14], [__consumer_offsets,41], [__consumer_offsets,42], [__consumer_offsets,4], [__consumer_offsets,12], [__consumer_offsets,21], [__consumer_offsets,30], [__consumer_offsets,1], [__consumer_offsets,32], [__consumer_offsets,13], [__consumer_offsets,8], [__consumer_offsets,20], [__consumer_offsets,0], [__consumer_offsets,29]) java.lang.NullPointerException at org.apache.kafka.common.utils.Utils.formatAddress(Utils.java:312) at kafka.cluster.Broker.connectionString(Broker.scala:62) at kafka.client.ClientUtils$$anonfun$fetchTopicMetadata$5.apply(ClientUtils.scala:89) at kafka.client.ClientUtils$$anonfun$fetchTopicMetadata$5.apply(ClientUtils.scala:89) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244) at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59) at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47) at scala.collection.TraversableLike$class.map(TraversableLike.scala:244) at scala.collection.AbstractTraversable.map(Traversable.scala:105) at kafka.client.ClientUtils$.fetchTopicMetadata(ClientUtils.scala:89) at kafka.consumer.ConsumerFetcherManager$LeaderFinderThread.doWork(ConsumerFetcherManager.scala:66) at kafka.utils.ShutdownableThread.run(ShutdownableThread.scala:60)以上,烦请解答。感谢
这个不支持认证,你需要换:
https://github.com/Morningstar/kafka-offset-monitor
需不需要改源码?直接用SBT打包吗?
请问有没有编译好的jar包可以提供?麻烦了,谢谢
https://github.com/Morningstar/kafka-offset-monitor/releases
有已经编译好的包,可以拿下来直接用。
你好,github上下载的源码按照你说的改完了那一个类,怎么用sbt/sbt assembly命令重新打包成jar文件啊,你那里有修改过的jar吗
你的安装sbt环境额。
https://www.orchome.com/sbt/index
大佬!kafkaMonitor的数据只能看到topic,其他的都没有,cmd命令能查看到,这是怎么回事
消费者启动了吗?另外你看下offset的位置是在Kafka还是zk上,上面有介绍
2.1.1的版本offset在kafka上面吧,--offsetStorage kafka 也只能看到主题,其他的都没有
WARN KafkaOffsetGetter$:89 - Failed to process one of the commit message due to exception. The 'bad' message will be skipped java.lang.RuntimeException: Unknown offset schema version 2 at com.quantifind.kafka.core.KafkaOffsetGetter$.schemaFor(KafkaOffsetGetter.scala:162) at com.quantifind.kafka.core.KafkaOffsetGetter$.com$quantifind$kafka$core$KafkaOffsetGetter$$readMessageKey(KafkaOffsetGetter.scala:187) at com.quantifind.kafka.core.KafkaOffsetGetter$$anonfun$startOffsetListener$1.apply$mcV$sp(KafkaOffsetGetter.scala:100) at com.quantifind.kafka.core.KafkaOffsetGetter$$anonfun$startOffsetListener$1.apply(KafkaOffsetGetter.scala:87) at com.quantifind.kafka.core.KafkaOffsetGetter$$anonfun$startOffsetListener$1.apply(KafkaOffsetGetter.scala:87) at scala.concurrent.impl.Future$PromiseCompletingRunnable.liftedTree1$1(Future.scala:24) at scala.concurrent.impl.Future$PromiseCompletingRunnable.run(Future.scala:24) at scala.concurrent.impl.ExecutionContextImpl$$anon$3.exec(ExecutionContextImpl.scala:107) at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260) at scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339) at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979) at scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)用的是2.2.0的版本,消费者启动后出现这个错误,用zk储存位置启动时,出现消费者组,但不是我创建的,kafka储存位置启动时还是什么都没有。zk和kafka一直显示的只有topic
我用的21.1的版本跟你一样的情况,也是这个错误,web也只能看到topic
package com.quantifind.kafka.core import java.nio.ByteBuffer import com.quantifind.kafka.OffsetGetter.OffsetInfo import com.quantifind.kafka.OffsetGetter import com.quantifind.utils.ZkUtilsWrapper import kafka.api.{OffsetRequest, PartitionOffsetRequestInfo} import kafka.common.{OffsetAndMetadata, TopicAndPartition} import kafka.consumer.{ConsumerConnector, KafkaStream} import kafka.message.MessageAndMetadata import kafka.utils.Logging import org.I0Itec.zkclient.ZkClient import scala.collection._ import scala.concurrent.ExecutionContext.Implicits.global import scala.concurrent.Future import scala.util.control.NonFatal class KafkaOffsetGetter(theZkClient: ZkClient, zkUtils: ZkUtilsWrapper = new ZkUtilsWrapper) extends OffsetGetter { import KafkaOffsetGetter._ override val zkClient = theZkClient override def processPartition(group: String, topic: String, pid: Int): Option[OffsetInfo] = { try { zkUtils.getLeaderForPartition(zkClient, topic, pid) match { case Some(bid) => val consumerOpt = consumerMap.getOrElseUpdate(bid, getConsumer(bid)) consumerOpt flatMap { consumer => val topicAndPartition = TopicAndPartition(topic, pid) offsetMap.get(GroupTopicPartition(group, topicAndPartition)) map { offsetMetaData => val request = OffsetRequest(immutable.Map(topicAndPartition -> PartitionOffsetRequestInfo(OffsetRequest.LatestTime, 1))) val logSize = consumer.getOffsetsBefore(request).partitionErrorAndOffsets(topicAndPartition).offsets.head OffsetInfo(group = group, topic = topic, partition = pid, offset = offsetMetaData.offset, logSize = logSize, owner = Some("NA")) } } case None => error("No broker for partition %s - %s".format(topic, pid)) None } } catch { case NonFatal(t) => error(s"Could not parse partition info. group: [$group] topic: [$topic]", t) None } } override def getGroups: Seq[String] = { topicAndGroups.groupBy(_.group).keySet.toSeq } override def getTopicList(group: String): List[String] = { topicAndGroups.filter(_.group == group).groupBy(_.topic).keySet.toList } override def getTopicMap: Map[String, scala.Seq[String]] = { topicAndGroups.groupBy(_.topic).mapValues(_.map(_.group).toSeq) } override def getActiveTopicMap: Map[String, Seq[String]] = { getTopicMap } } object KafkaOffsetGetterpicMap } } object KafkaOffsetGetter extends Logging { val ConsumerOffsetTopic = "__consumer_offsets" val offsetMap: mutable.Map[GroupTopicPartition, OffsetAndMetadata] = mutable.HashMap() val topicAndGroups: mutable.Set[TopicAndGroup] = mutable.HashSet() def startOffsetListener(consumerConnector: ConsumerConnector) = { Future { try { logger.info("Staring Kafka offset topic listener") val offsetMsgStream: KafkaStream[Array[Byte], Array[Byte]] = consumerConnector .createMessageStreams(Map(ConsumerOffsetTopic -> 1)) .get(ConsumerOffsetTopic).map(_.head) match { case Some(s) => s case None => throw new IllegalStateException("Cannot create a consumer stream on offset topic ") } val it = offsetMsgStream.iterator() while (true) { try { val offsetMsg: MessageAndMetadata[Array[Byte], Array[Byte]] = it.next() val commitKey: GroupTopicPartition = readMessageKey(ByteBuffer.wrap(offsetMsg.key())) val commitValue: OffsetAndMetadata = readMessageValue(ByteBuffer.wrap(offsetMsg.message())) info("Processed commit message: " + commitKey + " => " + commitValue) offsetMap += (commitKey -> commitValue) topicAndGroups += TopicAndGroupTopicAndGroupTopicAndGroup(commitKey.topicPartition.topic, commitKey.group) info(s"topicAndGroups = $topicAndGroups") } catch { case e: RuntimeException => // sometimes offsetMsg.key() || offsetMsg.message() throws NPE warn("Failed to process one of the commit message due to exception. The 'bad' message will be skipped", e) } } } catch { case e: Throwable => fatal("Offset topic listener aborted dur to unexpected exception", e) System.exit(1) } } } // massive code stealing from kafka.server.OffsetManager import java.nio.ByteBuffer import org.apache.kafka.common.protocol.types.Type.{INT32, INT64, STRING} import org.apache.kafka.common.protocol.types.{Field, Schema, Struct} private case class KeyAndValueSchemas(keySchema: Schema, valueSchema: Schema) private val OFFSET_COMMIT_KEY_SCHEMA_V0 = new Schema(new Field("group", STRING), new Field("topic", STRING), new Field("partition", INT32)) private val KEY_GROUP_FIELD = OFFSET_COMMIT_KEY_SCHEMA_V0.get("group") private val KEY_TOPIC_FIELD = OFFSET_COMMIT_KEY_SCHEMA_V0.get("topic") private val KEY_PARTITION_FIELD = OFFSET_COMMIT_KEY_SCHEMA_V0.get("partition") private val OFFSET_COMMIT_VALUE_SCHEMA_V0 = new Schema(new Field("offset", INT64), new Field("metadata", STRINGSTRING, "Associated metadata.", ""), new Fieldnew Field("timestamp", INT64INT64)) private val OFFSET_COMMIT_VALUE_SCHEMA_V1INT64)) private val OFFSET_COMMIT_VALUE_SCHEMA_V1 = new Schemanew Schema(new Field("offset", INT64), new Field("metadata", STRING, "Associated metadata.", ""), new Field("commit_timestamp", INT64), new Field("expire_timestamp", INT64)) private val OFFSET_COMMIT_VALUE_SCHEMA_V2 = new Schema(new Field("offset", INT64), new Field("metadata", STRING, "Associated metadata.", ""), new Field("commit_timestamp", INT64)) private val OFFSET_COMMIT_VALUE_SCHEMA_V3 = new Schema(new Field("offset", INT64), new Field("leader_epoch", INT32), new Field("metadata", STRING, "Associated metadata.", ""), new Field("commit_timestamp", INT64)) private val VALUE_OFFSET_FIELD_V0 = OFFSET_COMMIT_VALUE_SCHEMA_V0.get("offset") private val VALUE_METADATA_FIELD_V0 = OFFSET_COMMIT_VALUE_SCHEMA_V0.get("metadata") private val VALUE_TIMESTAMP_FIELD_V0 = OFFSET_COMMIT_VALUE_SCHEMA_V0.get("timestamp") private val VALUE_OFFSET_FIELD_V1 = OFFSET_COMMIT_VALUE_SCHEMA_V1.get("offset") private val VALUE_METADATA_FIELD_V1 = OFFSET_COMMIT_VALUE_SCHEMA_V1.get("metadata") private val VALUE_COMMIT_TIMESTAMP_FIELD_V1 = OFFSET_COMMIT_VALUE_SCHEMA_V1.get("commit_timestamp") private val VALUE_OFFSET_FIELD_V2 = OFFSET_COMMIT_VALUE_SCHEMA_V2.get("offset") private val VALUE_METADATA_FIELD_V2 = OFFSET_COMMIT_VALUE_SCHEMA_V2.get("metadata") private val VALUE_COMMIT_TIMESTAMP_FIELD_V2 = OFFSET_COMMIT_VALUE_SCHEMA_V2.get("commit_timestamp") private val VALUE_OFFSET_FIELD_V3 = OFFSET_COMMIT_VALUE_SCHEMA_V3.get("offset") private val VALUE_LEADER_EPOCH_FIELD_V3 = OFFSET_COMMIT_VALUE_SCHEMA_V3.get("leader_epoch") private val VALUE_METADATA_FIELD_V3 = OFFSET_COMMIT_VALUE_SCHEMA_V3.get("metadata") private val VALUE_COMMIT_TIMESTAMP_FIELD_V3 = OFFSET_COMMIT_VALUE_SCHEMA_V3.get("commit_timestamp") // private val VALUE_EXPIRE_TIMESTAMP_FIELD_V1 = OFFSET_COMMIT_VALUE_SCHEMA_V1.get("expire_timestamp") // map of versions to schemas private val OFFSET_SCHEMAS = Map(0 -> KeyAndValueSchemas(OFFSET_COMMIT_KEY_SCHEMA_V0, OFFSET_COMMIT_VALUE_SCHEMA_V0), 1 -> KeyAndValueSchemas(OFFSET_COMMIT_KEY_SCHEMA_V0, OFFSET_COMMIT_VALUE_SCHEMA_V1), 2 -> KeyAndValueSchemas(OFFSET_COMMIT_KEY_SCHEMA_V0, OFFSET_COMMIT_VALUE_SCHEMA_V2), 3 -> KeyAndValueSchemas(OFFSET_COMMIT_KEY_SCHEMA_V0, OFFSET_COMMIT_VALUE_SCHEMA_V3)) private def schemaFor(version: Int) = { val schemaOpt = OFFSET_SCHEMAS.get(version) schemaOpt matchsion) schemaOpt match { case java.nio.ByteBuffer import com.quantifind.kafka.OffsetGetter.OffsetInfo import com.quantifind.kafka.OffsetGetter import com.quantifind.utils.ZkUtilsWrapper import import kafka.api.{OffsetRequest, PartitionOffsetRequestInfo} import kafka.common.{OffsetAndMetadata, TopicAndPartition} import kafka.consumer.{ConsumerConnector, KafkaStream} import kafka.message.MessageAndMetadata import kafka.utils.Logging import org.I0Itec.zkclient.ZkClient import scala.collection._ import scala.concurrent.ExecutionContext.Implicits.global import scala.concurrent.Future import scala.util.control.NonFatal class KafkaOffsetGetter(theZkClient: ZkClient, zkUtils: ZkUtilsWrapper = new ZkUtilsWrapper) extends OffsetGetter { import KafkaOffsetGetter._ override val zkClient = theZkClient override def processPartition(group: String, topic: String, pid: Int): Option[OffsetInfo] = { try { zkUtils.getLeaderForPartition(zkClient, topic, pid) match { case Some(bid) => val consumerOpt = consumerMap.getOrElseUpdate(bid, getConsumer(bid)) consumerOpt flatMap { consumer => val topicAndPartition = TopicAndPartition(topic, pid) offsetMap.get(GroupTopicPartition(group, topicAndPartition)) map { offsetMetaData => val request = OffsetRequest(immutable.Map(topicAndPartition -> PartitionOffsetRequestInfo(OffsetRequest.LatestTime, 1))) val logSize = consumer.getOffsetsBefore(request).partitionErrorAndOffsets(topicAndPartition).offsets.head OffsetInfo(group = group, topic = topic, partition = pid, offset = offsetMetaData.offset, logSize = logSize, owner = Some("NA")) } } case NoneNone => error("No broker for partition %s - %s".format(topic, pid)) None } } catch { case NonFatal(t) => error(s"Could not parse partition info. group: [$group] topic: [$topic]", t) None } } override def getGroups: Seq[String] = { topicAndGroups.groupBy(_.group).keySet.toSeq } override def getTopicList(group: String): List[String] = { topicAndGroups.filter(_.group == group).groupBy(_.topic).keySet.toList } override def getTopicMap: Map[String, scala.Seq[String]] = { topicAndGroups.groupBy(_.topic).mapValues(_.map(_.group).toSeq) } override def getActiveTopicMap: Map[String, Seq[String]] = { getTopicMap } } object KafkaOffsetGetter extends Logging { val ConsumerOffsetTopic = "__consumer_offsets" val offsetMap: mutable.Map[GroupTopicPartition, OffsetAndMetadata] = mutable.HashMap() val topicAndGroups: mutable.Set[TopicAndGroup] = mutable.HashSet() def startOffsetListener(consumerConnector: ConsumerConnector) = { Future { try { logger.info("Staring Kafka offset topic listener") val offsetMsgStream: KafkaStream[Array[Byte], Array[Byte]] = consumerConnector .createMessageStreams(Map(ConsumerOffsetTopic -> 1)) .get(ConsumerOffsetTopic).map(_.head) match { case Some(s) => s case None => throw new IllegalStateException("Cannot create a consumer stream on offset topic ") } val it = offsetMsgStream.iterator() while (true) { try { val offsetMsg: MessageAndMetadata[Array[Byte], Array[Byte]] = it.next() val commitKey: GroupTopicPartition = readMessageKey(ByteBuffer.wrap(offsetMsg.key())) val commitValue: OffsetAndMetadata = readMessageValue(ByteBuffer.wrap(offsetMsg.message())) info("Processed commit message: " + commitKey + " => " + commitValue) offsetMap += (commitKey -> commitValue) topicAndGroups += TopicAndGroupTopicAndGroup(commitKey.topicPartition.topic, commitKey.group) info(s"topicAndGroups = $topicAndGroups") } catch { case e: RuntimeException => // sometimes offsetMsg.key() || offsetMsg.message() throws NPE warn("Failed to process one of the commit message due to exception. The 'bad' message will be skipped", e) } } } catch { case e: Throwable => fatal("Offset topic listener aborted dur to unexpected exception", e) System.exit(1) } } } // massive code stealing from kafka.server.OffsetManager import java.nio.ByteBuffer import org.apache.kafka.common.protocol.types.Type.{INT32, INT64, STRING} import org.apache.kafka.common.protocol.types.{Field, Schema, Struct} private case class KeyAndValueSchemas(keySchema: Schema, valueSchema: Schema) private val OFFSET_COMMIT_KEY_SCHEMA_V0 = new Schema(new Field("group", STRING), new Field("topic".quantifind.kafka.core import java.nio.ByteBuffer import com.quantifind.kafka.OffsetGetter.OffsetInfo import com.quantifind.kafka.OffsetGetter import com.quantifind.utils.ZkUtilsWrapper import kafka.api.{OffsetRequest, PartitionOffsetRequestInfo} import kafka.common.{OffsetAndMetadata, TopicAndPartition} import kafka.consumer.{ConsumerConnector, KafkaStream} import kafka.message.MessageAndMetadata import kafka.utils.Logging import org.I0Itec.zkclient.ZkClient import scala.collection._ import scala.concurrent.ExecutionContext.Implicits.global import scala.concurrent.Future import scala.util.control.NonFatal class KafkaOffsetGetter(theZkClient: ZkClient, zkUtils: ZkUtilsWrapper = new ZkUtilsWrapper) extends OffsetGetter { import KafkaOffsetGetter._ override val zkClient = theZkClient override def processPartition(group: String, topic: String, pid: Int): Option[OffsetInfo] = { try { zkUtils.getLeaderForPartition(zkClient, topic, pid) match { case Some(bid) => val consumerOptval= consumerMap.getOrElseUpdate(bid, getConsumer(bid)) consumerOpt flatMap { consumer => val topicAndPartition = TopicAndPartition(topic, pid) offsetMap.get(GroupTopicPartition(group, topicAndPartition)) map { offsetMetaData => val request = OffsetRequest(immutable.Map(topicAndPartition -> PartitionOffsetRequestInfo(OffsetRequest.LatestTime, 1))) val logSize = consumer.getOffsetsBefore(request).partitionErrorAndOffsets(topicAndPartition).offsets.head OffsetInfo(group = group, topic = topic, partition = pid, offset = offsetMetaData.offset, logSize = logSize, owner = Some("NA")) } } case None => error("No broker for partition %s - %s".format(topic, pid)) None } } catch { case NonFatal(t) => error(s"Could not parse partition info. group: [$group] topic: [$topic]", t) None } } override def getGroups: Seq[String] = { topicAndGroups.groupBy(_.group).keySet.toSeq } override def getTopicList(group: String): List[String] = { topicAndGroups.filter(_.group == group).groupBy(_.topic).keySet.toList } override def getTopicMap: Map[String, scala.Seq[String]] = { topicAndGroups.groupBy(_.topic).mapValues(_.map(_.group).toSeq) } override def getActiveTopicMap: Map[String, Seq[String]] = { getTopicMap } } object KafkaOffsetGetter extends Logging { val ConsumerOffsetTopic = "__consumer_offsets" val offsetMap: mutable.Map[GroupTopicPartition, OffsetAndMetadata] = mutable.HashMap() val topicAndGroups: mutable.Set[TopicAndGroup] = mutable.HashSet() def startOffsetListener(consumerConnector: ConsumerConnector) = { Future { try { logger.info("Staring Kafka offset topic listener") val offsetMsgStream: KafkaStream[Array[Byte], Array[Byte]] = consumerConnector .createMessageStreams(Map(ConsumerOffsetTopic -> 1)) .get(ConsumerOffsetTopic).map(_.head) match { case Some(s) => s case None => throw new IllegalStateException("Cannot create a consumer stream on offset topic ") } val it = offsetMsgStream.iterator() while (true) { try { val offsetMsg: MessageAndMetadata[Array[Byte], Array[Byte]] = it.next() val commitKey: GroupTopicPartition = readMessageKey(ByteBuffer.wrap(offsetMsg.key())) val commitValue: OffsetAndMetadata = readMessageValue(ByteBuffer.wrap(offsetMsg.message())) info("Processed commit message: " + commitKey + " => " + commitValue) offsetMap += (commitKey -> commitValue) topicAndGroups += TopicAndGroup(commitKey.topicPartition.topic, commitKey.group) info(s"topicAndGroups = $topicAndGroups") } catch { case e: RuntimeException => // sometimes offsetMsg.key() || offsetMsg.message() throws NPE warn("Failed to process one of the commit message due to exception. The 'bad' message will be skipped", e) } } } catch { case e: Throwable => fatal("Offset topic listener aborted dur to unexpected exception", e) System.exit(1) } } } // massive code stealing from kafka.server.OffsetManager import java.nio.ByteBuffer import org.apache.kafka.common.protocol.types.Type.{INT32, INT64, STRING} import org.apache.kafka.common.protocol.types.{Field, Schema, Struct} private case class KeyAndValueSchemas(keySchema: Schema, valueSchema: Schema) private val OFFSET_COMMIT_KEY_SCHEMA_V0 = new Schema(new Field("group", STRING), new Field("topic", STRING), new Field("partition", INT32)) private val KEY_GROUP_FIELD = OFFSET_COMMIT_KEY_SCHEMA_V0.get("group") private val KEY_TOPIC_FIELD = OFFSET_COMMIT_KEY_SCHEMA_V0.get("topic") private val KEY_PARTITION_FIELD = OFFSET_COMMIT_KEY_SCHEMA_V0.get("partition") private val OFFSET_COMMIT_VALUE_SCHEMA_V0 = new Schema(new Field("offset", INT64), new Field("metadata", STRING, "Associated metadata.", ""), new Field("timestamp", INT64)) private val OFFSET_COMMIT_VALUE_SCHEMA_V1 = new Schema(new Field("offset", INT64), new Field("metadata", STRING, "Associated metadata.", ""), new Field("commit_timestamp", INT64), new Field("expire_timestamp", INT64)) private val OFFSET_COMMIT_VALUE_SCHEMA_V2 = new Schema(new Field("offset", INT64), new Field("metadata", STRING, "Associated metadata.", ""), new Field("commit_timestamp", INT64)) private val OFFSET_COMMIT_VALUE_SCHEMA_V3 = new Schema(new Field("offset", INT64), new Field("leader_epoch", INT32), new Field("metadata", STRING, "Associated metadata.", ""), new Field("commit_timestamp", INT64)) private val VALUE_OFFSET_FIELD_V0 = OFFSET_COMMIT_VALUE_SCHEMA_V0.get("offset") private val VALUE_METADATA_FIELD_V0 = OFFSET_COMMIT_VALUE_SCHEMA_V0.get("metadata") private val VALUE_TIMESTAMP_FIELD_V0 = OFFSET_COMMIT_VALUE_SCHEMA_V0.get("timestamp") private val VALUE_OFFSET_FIELD_V1 = OFFSET_COMMIT_VALUE_SCHEMA_V1.get("offset") private val VALUE_METADATA_FIELD_V1 = OFFSET_COMMIT_VALUE_SCHEMA_V1.get("metadata") private val VALUE_COMMIT_TIMESTAMP_FIELD_V1 = OFFSET_COMMIT_VALUE_SCHEMA_V1.get("commit_timestamp") private val VALUE_OFFSET_FIELD_V2 = OFFSET_COMMIT_VALUE_SCHEMA_V2.get("offset") private val VALUE_METADATA_FIELD_V2 = OFFSET_COMMIT_VALUE_SCHEMA_V2.get("metadata") private val VALUE_COMMIT_TIMESTAMP_FIELD_V2 = OFFSET_COMMIT_VALUE_SCHEMA_V2.get("commit_timestamp") private val VALUE_OFFSET_FIELD_V3 = OFFSET_COMMIT_VALUE_SCHEMA_V3.get("offset") private val VALUE_LEADER_EPOCH_FIELD_V3 = OFFSET_COMMIT_VALUE_SCHEMA_V3.get("leader_epoch") private val VALUE_METADATA_FIELD_V3 = OFFSET_COMMIT_VALUE_SCHEMA_V3.get("metadata") private val VALUE_COMMIT_TIMESTAMP_FIELD_V3 = OFFSET_COMMIT_VALUE_SCHEMA_V3.get("commit_timestamp") // private val VALUE_EXPIRE_TIMESTAMP_FIELD_V1 = OFFSET_COMMIT_VALUE_SCHEMA_V1.get("expire_timestamp") // map of versions to schemas private val OFFSET_SCHEMAS = Map(0 -> KeyAndValueSchemas(OFFSET_COMMIT_KEY_SCHEMA_V0, OFFSET_COMMIT_VALUE_SCHEMA_V0), 1 -> KeyAndValueSchemas(OFFSET_COMMIT_KEY_SCHEMA_V0, OFFSET_COMMIT_VALUE_SCHEMA_V1), 2 -> KeyAndValueSchemas(OFFSET_COMMIT_KEY_SCHEMA_V0, OFFSET_COMMIT_VALUE_SCHEMA_V2), 3 -> KeyAndValueSchemas(OFFSET_COMMIT_KEY_SCHEMA_V0, OFFSET_COMMIT_VALUE_SCHEMA_V3)) private def schemaFor(version: Int) = { val schemaOpt = OFFSET_SCHEMAS.get(version) schemaOpt match { case Some(schema) => schema case _ => throw new RuntimeException("Unknown offset schema version " + version) } } case class MessageValueStructAndVersion(value: Struct, version: Short) case class TopicAndGroup(topic: String, group: String) case class GroupTopicPartition(group: String, topicPartition: TopicAndPartition) { def this(group: String, topic: String, partition: Int) = this(group, new TopicAndPartition(topic, partition)) override def toString = "[%s,%s,%d]".format(group, topicPartition.topic, topicPartition.partition) } /** * Decodes the offset messages' key * * @param buffer input byte-buffer * @return an GroupTopicPartition object */ private def readMessageKey(buffer: ByteBuffer): GroupTopicPartition = { val version = buffer.getShort() val keySchema = schemaFor(version).keySchema val key = keySchema.read(buffer).asInstanceOf[Struct] val group = key.get(KEY_GROUP_FIELD).asInstanceOf[String] val topic = key.get(KEY_TOPIC_FIELD).asInstanceOf[String] val partition = key.get(KEY_PARTITION_FIELD).asInstanceOf[Int] GroupTopicPartition(group, TopicAndPartition(topic, partition)) } /** * Decodes the offset messages' payload and retrieves offset and metadata from it * * @param buffer input byte-buffer * @return an offset-metadata object from the message */ private def readMessageValue(buffer: ByteBuffer): OffsetAndMetadata = { val structAndVersion = readMessageValueStruct(buffer) if (structAndVersion.value == null) { // tombstone null } else { if (structAndVersion.version == 0) { val offset = structAndVersion.value.get(VALUE_OFFSET_FIELD_V0).asInstanceOf[Long] val metadata = structAndVersion.value.get(VALUE_METADATA_FIELD_V0).asInstanceOf[String] val timestamp = structAndVersion.value.get(VALUE_TIMESTAMP_FIELD_V0).asInstanceOf[Long] OffsetAndMetadata(offset, metadata, timestamp) } else if (structAndVersion.version == 1) { val offset = structAndVersion.value.get(VALUE_OFFSET_FIELD_V1).asInstanceOf[Long] val metadata = structAndVersion.value.get(VALUE_METADATA_FIELD_V1).asInstanceOf[String] val commitTimestamp = structAndVersion.value.get(VALUE_COMMIT_TIMESTAMP_FIELD_V1).asInstanceOf[Long] // not supported in 0.8.2 // val expireTimestamp = structAndVersion.value.get(VALUE_EXPIRE_TIMESTAMP_FIELD_V1).asInstanceOf[Long] OffsetAndMetadata(offset, metadata, commitTimestamp) } else if (structAndVersion.version == 2) { val offset = structAndVersion.value.get(VALUE_OFFSET_FIELD_V2).asInstanceOf[Long] val metadata = structAndVersion.value.get(VALUE_METADATA_FIELD_V2).asInstanceOf[String] val commitTimestamp = structAndVersion.value.get(VALUE_COMMIT_TIMESTAMP_FIELD_V2).asInstanceOf[Long] // not supported in 0.8.2 // val expireTimestamp = structAndVersion.value.get(VALUE_EXPIRE_TIMESTAMP_FIELD_V1).asInstanceOf[Long] OffsetAndMetadata(offset, metadata, commitTimestamp) }else if(structAndVersion.version == 3){ val offset = structAndVersion.value.get(VALUE_OFFSET_FIELD_V3).asInstanceOf[Long] val metadata = structAndVersion.value.get(VALUE_METADATA_FIELD_V3).asInstanceOf[String] val commitTimestamp = structAndVersion.value.get(VALUE_COMMIT_TIMESTAMP_FIELD_V3).asInstanceOf[Long] // not supported in 0.8.2 // val expireTimestamp = structAndVersion.value.get(VALUE_EXPIRE_TIMESTAMP_FIELD_V1).asInstanceOf[Long] OffsetAndMetadata(offset, metadata, commitTimestamp) } else { throw new IllegalStateException("Unknown offset message version: " + structAndVersion.version) } } } private def readMessageValueStruct(buffer: ByteBuffer): MessageValueStructAndVersion = { if(buffer == null) { // tombstone MessageValueStructAndVersion(null, -1) } else { val version = buffer.getShort() val valueSchema = schemaFor(version).valueSchema val value = valueSchema.read(buffer).asInstanceOf[Struct] MessageValueStructAndVersion(value, version) } } }改下源码,这个类的代码改成这样就好了
请问大佬应该怎么改呀,是先反编译为.java文件然后替换这些代码,还是直接替换.class文件里的代码呀
2019-08-16 10:02:27 WARN KafkaOffsetGetter$:89 - Failed to process one of the commit message due to exception. The 'bad' message will be skipped java.lang.RuntimeException: Unknown offset schema version 3 at com.quantifind.kafka.core.KafkaOffsetGetter$.schemaFor(KafkaOffsetGetter.scala:162) at com.quantifind.kafka.core.KafkaOffsetGetter$.readMessageValueStruct(KafkaOffsetGetter.scala:234) at com.quantifind.kafka.core.KafkaOffsetGetter$.com$quantifind$kafka$core$KafkaOffsetGetter$$readMessageValue(KafkaOffsetGetter.scala:204) at com.quantifind.kafka.core.KafkaOffsetGetter$$anonfun$startOffsetListener$1.apply$mcV$sp(KafkaOffsetGetter.scala:101) at com.quantifind.kafka.core.KafkaOffsetGetter$$anonfun$startOffsetListener$1.apply(KafkaOffsetGetter.scala:87) at com.quantifind.kafka.core.KafkaOffsetGetter$$anonfun$startOffsetListener$1.apply(KafkaOffsetGetter.scala:87) at scala.concurrent.impl.Future$PromiseCompletingRunnable.liftedTree1$1(Future.scala:24) at scala.concurrent.impl.Future$PromiseCompletingRunnable.run(Future.scala:24) at scala.concurrent.impl.ExecutionContextImpl$$anon$3.exec(ExecutionContextImpl.scala:107) at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260) at scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339) at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979) at scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)jdk版本:jdk1.8.0_181
kafka 版本:kafka_2.12-2.1.1
zookeeper版本:zookeeper-3.4.14
KafkaOffsetMonitor启动命令
java -cp KafkaOffsetMonitor-assembly-0.3.0-SNAPSHOT.jar \ com.quantifind.kafka.offsetapp.OffsetGetterWeb \ --offsetStorage kafka \ --zk zkServer1:12181,zkServer2:12181 \ --port 8088 \ --refresh 10.seconds \ --retain 2.days一直在刷这个错误,web端也没监控到任何生产和消费,不知道是scala版本还是kafka版本不对
package com.quantifind.kafka.core import java.nio.ByteBuffer import com.quantifind.kafka.OffsetGetter.OffsetInfo import com.quantifind.kafka.OffsetGetter import com.quantifind.utils.ZkUtilsWrapper import kafka.api.{OffsetRequest, PartitionOffsetRequestInfo} import kafka.common.{OffsetAndMetadata, TopicAndPartition} import kafka.consumer.{ConsumerConnector, KafkaStream} import kafka.message.MessageAndMetadata import kafka.utils.Logging import org.I0Itec.zkclient.ZkClient import scala.collection._ import scala.concurrent.ExecutionContext.Implicits.global import scala.concurrent.Future import scala.util.control.NonFatal class KafkaOffsetGetter(theZkClient: ZkClient, zkUtils: ZkUtilsWrapper = new ZkUtilsWrapper) extends OffsetGetter { import KafkaOffsetGetter._ override val zkClient = theZkClient override def processPartition(group: String, topic: String, pid: Int): Option[OffsetInfo] = { try { zkUtils.getLeaderForPartition(zkClient, topic, pid) match { case Some(bid) => val consumerOpt = consumerMap.getOrElseUpdate(bid, getConsumer(bid)) consumerOpt flatMap { consumer => val topicAndPartition = TopicAndPartition(topic, pid) offsetMap.get(GroupTopicPartition(group, topicAndPartition)) map { offsetMetaData => val request = OffsetRequest(immutable.Map(topicAndPartition -> PartitionOffsetRequestInfo(OffsetRequest.LatestTime, 1))) val logSize = consumer.getOffsetsBefore(request).partitionErrorAndOffsets(topicAndPartition).offsets.head OffsetInfo(group = group, topic = topic, partition = pid, offset = offsetMetaData.offset, logSize = logSize, owner = Some("NA")) } } case None => error("No broker for partition %s - %s".format(topic, pid)) None } } catch { case NonFatal(t) => error(s"Could not parse partition info. group: [$group] topic: [$topic]", t) None } } override def getGroups: Seq[String] = { topicAndGroups.groupBy(_.group).keySet.toSeq } override def getTopicList(group: String): List[String] = { topicAndGroups.filter(_.group == group).groupBy(_.topic).keySet.toList } override def getTopicMap: Map[String, scala.Seq[String]] = { topicAndGroups.groupBy(_.topic).mapValues(_.map(_.group).toSeq) } override def getActiveTopicMap: Map[String, Seq[String]] = { getTopicMap } } object KafkaOffsetGetter extends Logging { val ConsumerOffsetTopic = "__consumer_offsets" val offsetMap: mutable.Map[GroupTopicPartition, OffsetAndMetadata] = mutable.HashMap() val topicAndGroups: mutable.Set[TopicAndGroup] = mutable.HashSet() def startOffsetListener(consumerConnector: ConsumerConnector) = { Future { try { logger.info("Staring Kafka offset topic listener") val offsetMsgStream: KafkaStream[Array[Byte], Array[Byte]] = consumerConnector .createMessageStreams(Map(ConsumerOffsetTopic -> 1)) .get(ConsumerOffsetTopic).map(_.head) match { case Some(s) => s case None => throw new IllegalStateException("Cannot create a consumer stream on offset topic ") } val it = offsetMsgStream.iterator() while (true) { try { val offsetMsg: MessageAndMetadata[Array[Byte], Array[Byte]] = it.next() val commitKey: GroupTopicPartition = readMessageKey(ByteBuffer.wrap(offsetMsg.key())) val commitValue: OffsetAndMetadata = readMessageValue(ByteBuffer.wrap(offsetMsg.message())) info("Processed commit message: " + commitKey + " => " + commitValue) offsetMap += (commitKey -> commitValue) topicAndGroups += TopicAndGroup(commitKey.topicPartition.topic, commitKey.group) info(s"topicAndGroups = $topicAndGroups") } catch { case e: RuntimeException => // sometimes offsetMsg.key() || offsetMsg.message() throws NPE warn("Failed to process one of the commit message due to exception. The 'bad' message will be skipped", e) } } } catch { case e: Throwable => fatal("Offset topic listener aborted dur to unexpected exception", e) System.exit(1) } } } // massive code stealing from kafka.server.OffsetManager import java.nio.ByteBuffer import org.apache.kafka.common.protocol.types.Type.{INT32, INT64, STRING} import org.apache.kafka.common.protocol.types.{Field, Schema, Struct} private case class KeyAndValueSchemas(keySchema: Schema, valueSchema: Schema) private val OFFSET_COMMIT_KEY_SCHEMA_V0 = new Schema(new Field("group", STRING), new Field("topic", STRING), new Field("partition", INT32)) private val KEY_GROUP_FIELD = OFFSET_COMMIT_KEY_SCHEMA_V0.get("group") private val KEY_TOPIC_FIELD = OFFSET_COMMIT_KEY_SCHEMA_V0.get("topic") private val KEY_PARTITION_FIELD = OFFSET_COMMIT_KEY_SCHEMA_V0.get("partition") private val OFFSET_COMMIT_VALUE_SCHEMA_V0 = new Schema(new Field("offset", INT64), new Field("metadata", STRING, "Associated metadata.", ""), new Field("timestamp", INT64)) private val OFFSET_COMMIT_VALUE_SCHEMA_V1 = new Schema(new Field("offset", INT64), new Field("metadata", STRING, "Associated metadata.", ""), new Field("commit_timestamp", INT64), new Field("expire_timestamp", INT64)) private val OFFSET_COMMIT_VALUE_SCHEMA_V2 = new Schema(new Field("offset", INT64), new Field("metadata", STRING, "Associated metadata.", ""), new Field("commit_timestamp", INT64)) private val OFFSET_COMMIT_VALUE_SCHEMA_V3 = new Schema(new Field("offset", INT64), new Field("leader_epoch", INT32), new Field("metadata", STRING, "Associated metadata.", ""), new Field("commit_timestamp", INT64)) private val VALUE_OFFSET_FIELD_V0 = OFFSET_COMMIT_VALUE_SCHEMA_V0.get("offset") private val VALUE_METADATA_FIELD_V0 = OFFSET_COMMIT_VALUE_SCHEMA_V0.get("metadata") private val VALUE_TIMESTAMP_FIELD_V0 = OFFSET_COMMIT_VALUE_SCHEMA_V0.get("timestamp") private val VALUE_OFFSET_FIELD_V1 = OFFSET_COMMIT_VALUE_SCHEMA_V1.get("offset") private val VALUE_METADATA_FIELD_V1 = OFFSET_COMMIT_VALUE_SCHEMA_V1.get("metadata") private val VALUE_COMMIT_TIMESTAMP_FIELD_V1 = OFFSET_COMMIT_VALUE_SCHEMA_V1.get("commit_timestamp") private val VALUE_OFFSET_FIELD_V2 = OFFSET_COMMIT_VALUE_SCHEMA_V2.get("offset") private val VALUE_METADATA_FIELD_V2 = OFFSET_COMMIT_VALUE_SCHEMA_V2.get("metadata") private val VALUE_COMMIT_TIMESTAMP_FIELD_V2 = OFFSET_COMMIT_VALUE_SCHEMA_V2.get("commit_timestamp") private val VALUE_OFFSET_FIELD_V3 = OFFSET_COMMIT_VALUE_SCHEMA_V3.get("offset") private val VALUE_LEADER_EPOCH_FIELD_V3 = OFFSET_COMMIT_VALUE_SCHEMA_V3.get("leader_epoch") private val VALUE_METADATA_FIELD_V3 = OFFSET_COMMIT_VALUE_SCHEMA_V3.get("metadata") private val VALUE_COMMIT_TIMESTAMP_FIELD_V3 = OFFSET_COMMIT_VALUE_SCHEMA_V3.get("commit_timestamp") // private val VALUE_EXPIRE_TIMESTAMP_FIELD_V1 = OFFSET_COMMIT_VALUE_SCHEMA_V1.get("expire_timestamp") // map of versions to schemas private val OFFSET_SCHEMAS = Map(0 -> KeyAndValueSchemas(OFFSET_COMMIT_KEY_SCHEMA_V0, OFFSET_COMMIT_VALUE_SCHEMA_V0), 1 -> KeyAndValueSchemas(OFFSET_COMMIT_KEY_SCHEMA_V0, OFFSET_COMMIT_VALUE_SCHEMA_V1), 2 -> KeyAndValueSchemas(OFFSET_COMMIT_KEY_SCHEMA_V0, OFFSET_COMMIT_VALUE_SCHEMA_V2), 3 -> KeyAndValueSchemas(OFFSET_COMMIT_KEY_SCHEMA_V0, OFFSET_COMMIT_VALUE_SCHEMA_V3)) private def schemaFor(version: Int) = { val schemaOpt = OFFSET_SCHEMAS.get(version) schemaOpt match { case Some(schema) => schema case _ => throw new RuntimeException("Unknown offset schema version " + version) } } case class MessageValueStructAndVersion(value: Struct, version: Short) case class TopicAndGroup(topic: String, group: String) case class GroupTopicPartition(group: String, topicPartition: TopicAndPartition) { def this(group: String, topic: String, partition: Int) = this(group, new TopicAndPartition(topic, partition)) override def toString = "[%s,%s,%d]".format(group, topicPartition.topic, topicPartition.partition) } /** * Decodes the offset messages' key * * @param buffer input byte-buffer * @return an GroupTopicPartition object */ private def readMessageKey(buffer: ByteBuffer): GroupTopicPartition = { val version = buffer.getShort() val keySchema = schemaFor(version).keySchema val key = keySchema.read(buffer).asInstanceOf[Struct] val group = key.get(KEY_GROUP_FIELD).asInstanceOf[String] val topic = key.get(KEY_TOPIC_FIELD).asInstanceOf[String] val partition = key.get(KEY_PARTITION_FIELD).asInstanceOf[Int] GroupTopicPartition(group, TopicAndPartition(topic, partition)) } /** * Decodes the offset messages' payload and retrieves offset and metadata from it * * @param buffer input byte-buffer * @return an offset-metadata object from the message */ private def readMessageValue(buffer: ByteBuffer): OffsetAndMetadata = { val structAndVersion = readMessageValueStruct(buffer) if (structAndVersion.value == null) { // tombstone null } else { if (structAndVersion.version == 0) { val offset = structAndVersion.value.get(VALUE_OFFSET_FIELD_V0).asInstanceOf[Long] val metadata = structAndVersion.value.get(VALUE_METADATA_FIELD_V0).asInstanceOf[String] val timestamp = structAndVersion.value.get(VALUE_TIMESTAMP_FIELD_V0).asInstanceOf[Long] OffsetAndMetadata(offset, metadata, timestamp) } else if (structAndVersion.version == 1) { val offset = structAndVersion.value.get(VALUE_OFFSET_FIELD_V1).asInstanceOf[Long] val metadata = structAndVersion.value.get(VALUE_METADATA_FIELD_V1).asInstanceOf[String] val commitTimestamp = structAndVersion.value.get(VALUE_COMMIT_TIMESTAMP_FIELD_V1).asInstanceOf[Long] // not supported in 0.8.2 // val expireTimestamp = structAndVersion.value.get(VALUE_EXPIRE_TIMESTAMP_FIELD_V1).asInstanceOf[Long] OffsetAndMetadata(offset, metadata, commitTimestamp) } else if (structAndVersion.version == 2) { val offset = structAndVersion.value.get(VALUE_OFFSET_FIELD_V2).asInstanceOf[Long] val metadata = structAndVersion.value.get(VALUE_METADATA_FIELD_V2).asInstanceOf[String] val commitTimestamp = structAndVersion.value.get(VALUE_COMMIT_TIMESTAMP_FIELD_V2).asInstanceOf[Long] // not supported in 0.8.2 // val expireTimestamp = structAndVersion.value.get(VALUE_EXPIRE_TIMESTAMP_FIELD_V1).asInstanceOf[Long] OffsetAndMetadata(offset, metadata, commitTimestamp) }else if(structAndVersion.version == 3){ val offset = structAndVersion.value.get(VALUE_OFFSET_FIELD_V3).asInstanceOf[Long] val metadata = structAndVersion.value.get(VALUE_METADATA_FIELD_V3).asInstanceOf[String] val commitTimestamp = structAndVersion.value.get(VALUE_COMMIT_TIMESTAMP_FIELD_V3).asInstanceOf[Long] // not supported in 0.8.2 // val expireTimestamp = structAndVersion.value.get(VALUE_EXPIRE_TIMESTAMP_FIELD_V1).asInstanceOf[Long] OffsetAndMetadata(offset, metadata, commitTimestamp) } else { throw new IllegalStateException("Unknown offset message version: " + structAndVersion.version) } } } private def readMessageValueStruct(buffer: ByteBuffer): MessageValueStructAndVersion = { if(buffer == null) { // tombstone MessageValueStructAndVersion(null, -1) } else { val version = buffer.getShort() val valueSchema = schemaFor(version).valueSchema val value = valueSchema.read(buffer).asInstanceOf[Struct] MessageValueStructAndVersion(value, version) } } }改下源码
解决了吗?我也是一直刷这个错误
2019-07-16 17:30:21 WARN KafkaOffsetGetter$:89 - Failed to process one of the c ommit message due to exception. The 'bad' message will be skipped java.lang.RuntimeException: Unknown offset schema version 3请问这个错误是什么意思
警告,忽视吧
package com.quantifind.kafka.core import java.nio.ByteBuffer import com.quantifind.kafka.OffsetGetter.OffsetInfo import com.quantifind.kafka.OffsetGetter import com.quantifind.utils.ZkUtilsWrapper import kafka.api.{OffsetRequest, PartitionOffsetRequestInfo} import kafka.common.{OffsetAndMetadata, TopicAndPartition} import kafka.consumer.{ConsumerConnector, KafkaStream} import kafka.message.MessageAndMetadata import kafka.utils.Logging import org.I0Itec.zkclient.ZkClient import scala.collection._ import scala.concurrent.ExecutionContext.Implicits.global import scala.concurrent.Future import scala.util.control.NonFatal class KafkaOffsetGetter(theZkClient: ZkClient, zkUtils: ZkUtilsWrapper = new ZkUtilsWrapper) extends OffsetGetter { import KafkaOffsetGetter._ override val zkClient = theZkClient override def processPartition(group: String, topic: String, pid: Int): Option[OffsetInfo] = { try { zkUtils.getLeaderForPartition(zkClient, topic, pid) match { case Some(bid) => val consumerOpt = consumerMap.getOrElseUpdate(bid, getConsumer(bid)) consumerOpt flatMap { consumer => val topicAndPartition = TopicAndPartition(topic, pid) offsetMap.get(GroupTopicPartition(group, topicAndPartition)) map { offsetMetaData => val request = OffsetRequest(immutable.Map(topicAndPartition -> PartitionOffsetRequestInfo(OffsetRequest.LatestTime, 1))) val logSize = consumer.getOffsetsBefore(request).partitionErrorAndOffsets(topicAndPartition).offsets.head OffsetInfo(group = group, topic = topic, partition = pid, offset = offsetMetaData.offset, logSize = logSize, owner = Some("NA")) } } case None => error("No broker for partition %s - %s".format(topic, pid)) None } } catch { case NonFatal(t) => error(s"Could not parse partition info. group: [$group] topic: [$topic]", t) None } } override def getGroups: Seq[String] = { topicAndGroups.groupBy(_.group).keySet.toSeq } override def getTopicList(group: String): List[String] = { topicAndGroups.filter(_.group == group).groupBy(_.topic).keySet.toList } override def getTopicMap: Map[String, scala.Seq[String]] = { topicAndGroups.groupBy(_.topic).mapValues(_.map(_.group).toSeq) } override def getActiveTopicMap: Map[String, Seq[String]] = { getTopicMap } } object KafkaOffsetGetter extends Logging { val ConsumerOffsetTopic = "__consumer_offsets" val offsetMap: mutable.Map[GroupTopicPartition, OffsetAndMetadata] = mutable.HashMap() val topicAndGroups: mutable.Set[TopicAndGroup] = mutable.HashSet() def startOffsetListener(consumerConnector: ConsumerConnector) = { Future { try { logger.info("Staring Kafka offset topic listener") val offsetMsgStream: KafkaStream[Array[Byte], Array[Byte]] = consumerConnector .createMessageStreams(Map(ConsumerOffsetTopic -> 1)) .get(ConsumerOffsetTopic).map(_.head) match { case Some(s) => s case None => throw new IllegalStateException("Cannot create a consumer stream on offset topic ") } val it = offsetMsgStream.iterator() while (true) { try { val offsetMsg: MessageAndMetadata[Array[Byte], Array[Byte]] = it.next() val commitKey: GroupTopicPartition = readMessageKey(ByteBuffer.wrap(offsetMsg.key())) val commitValue: OffsetAndMetadata = readMessageValue(ByteBuffer.wrap(offsetMsg.message())) info("Processed commit message: " + commitKey + " => " + commitValue) offsetMap += (commitKey -> commitValue) topicAndGroups += TopicAndGroup(commitKey.topicPartition.topic, commitKey.group) info(s"topicAndGroups = $topicAndGroups") } catch { case e: RuntimeException => // sometimes offsetMsg.key() || offsetMsg.message() throws NPE warn("Failed to process one of the commit message due to exception. The 'bad' message will be skipped", e) } } } catch { case e: Throwable => fatal("Offset topic listener aborted dur to unexpected exception", e) System.exit(1) } } } // massive code stealing from kafka.server.OffsetManager import java.nio.ByteBuffer import org.apache.kafka.common.protocol.types.Type.{INT32, INT64, STRING} import org.apache.kafka.common.protocol.types.{Field, Schema, Struct} private case class KeyAndValueSchemas(keySchema: Schema, valueSchema: Schema) private val OFFSET_COMMIT_KEY_SCHEMA_V0 = new Schema(new Field("group", STRING), new Field("topic", STRING), new Field("partition", INT32)) private val KEY_GROUP_FIELD = OFFSET_COMMIT_KEY_SCHEMA_V0.get("group") private val KEY_TOPIC_FIELD = OFFSET_COMMIT_KEY_SCHEMA_V0.get("topic") private val KEY_PARTITION_FIELD = OFFSET_COMMIT_KEY_SCHEMA_V0.get("partition") private val OFFSET_COMMIT_VALUE_SCHEMA_V0 = new Schema(new Field("offset", INT64), new Field("metadata", STRING, "Associated metadata.", ""), new Field("timestamp", INT64)) private val OFFSET_COMMIT_VALUE_SCHEMA_V1 = new Schema(new Field("offset", INT64), new Field("metadata", STRING, "Associated metadata.", ""), new Field("commit_timestamp", INT64), new Field("expire_timestamp", INT64)) private val OFFSET_COMMIT_VALUE_SCHEMA_V2 = new Schema(new Field("offset", INT64), new Field("metadata", STRING, "Associated metadata.", ""), new Field("commit_timestamp", INT64)) private val OFFSET_COMMIT_VALUE_SCHEMA_V3 = new Schema(new Field("offset", INT64), new Field("leader_epoch", INT32), new Field("metadata", STRING, "Associated metadata.", ""), new Field("commit_timestamp", INT64)) private val VALUE_OFFSET_FIELD_V0 = OFFSET_COMMIT_VALUE_SCHEMA_V0.get("offset") private val VALUE_METADATA_FIELD_V0 = OFFSET_COMMIT_VALUE_SCHEMA_V0.get("metadata") private val VALUE_TIMESTAMP_FIELD_V0 = OFFSET_COMMIT_VALUE_SCHEMA_V0.get("timestamp") private val VALUE_OFFSET_FIELD_V1 = OFFSET_COMMIT_VALUE_SCHEMA_V1.get("offset") private val VALUE_METADATA_FIELD_V1 = OFFSET_COMMIT_VALUE_SCHEMA_V1.get("metadata") private val VALUE_COMMIT_TIMESTAMP_FIELD_V1 = OFFSET_COMMIT_VALUE_SCHEMA_V1.get("commit_timestamp") private val VALUE_OFFSET_FIELD_V2 = OFFSET_COMMIT_VALUE_SCHEMA_V2.get("offset") private val VALUE_METADATA_FIELD_V2 = OFFSET_COMMIT_VALUE_SCHEMA_V2.get("metadata") private val VALUE_COMMIT_TIMESTAMP_FIELD_V2 = OFFSET_COMMIT_VALUE_SCHEMA_V2.get("commit_timestamp") private val VALUE_OFFSET_FIELD_V3 = OFFSET_COMMIT_VALUE_SCHEMA_V3.get("offset") private val VALUE_LEADER_EPOCH_FIELD_V3 = OFFSET_COMMIT_VALUE_SCHEMA_V3.get("leader_epoch") private val VALUE_METADATA_FIELD_V3 = OFFSET_COMMIT_VALUE_SCHEMA_V3.get("metadata") private val VALUE_COMMIT_TIMESTAMP_FIELD_V3 = OFFSET_COMMIT_VALUE_SCHEMA_V3.get("commit_timestamp") // private val VALUE_EXPIRE_TIMESTAMP_FIELD_V1 = OFFSET_COMMIT_VALUE_SCHEMA_V1.get("expire_timestamp") // map of versions to schemas private val OFFSET_SCHEMAS = Map(0 -> KeyAndValueSchemas(OFFSET_COMMIT_KEY_SCHEMA_V0, OFFSET_COMMIT_VALUE_SCHEMA_V0), 1 -> KeyAndValueSchemas(OFFSET_COMMIT_KEY_SCHEMA_V0, OFFSET_COMMIT_VALUE_SCHEMA_V1), 2 -> KeyAndValueSchemas(OFFSET_COMMIT_KEY_SCHEMA_V0, OFFSET_COMMIT_VALUE_SCHEMA_V2), 3 -> KeyAndValueSchemas(OFFSET_COMMIT_KEY_SCHEMA_V0, OFFSET_COMMIT_VALUE_SCHEMA_V3)) private def schemaFor(version: Int) = { val schemaOpt = OFFSET_SCHEMAS.get(version) schemaOpt match { case Some(schema) => schema case _ => throw new RuntimeException("Unknown offset schema version " + version) } } case class MessageValueStructAndVersion(value: Struct, version: Short) case class TopicAndGroup(topic: String, group: String) case class GroupTopicPartition(group: String, topicPartition: TopicAndPartition) { def this(group: String, topic: String, partition: Int) = this(group, new TopicAndPartition(topic, partition)) override def toString = "[%s,%s,%d]".format(group, topicPartition.topic, topicPartition.partition) } /** * Decodes the offset messages' key * * @param buffer input byte-buffer * @return an GroupTopicPartition object */ private def readMessageKey(buffer: ByteBuffer): GroupTopicPartition = { val version = buffer.getShort() val keySchema = schemaFor(version).keySchema val key = keySchema.read(buffer).asInstanceOf[Struct] val group = key.get(KEY_GROUP_FIELD).asInstanceOf[String] val topic = key.get(KEY_TOPIC_FIELD).asInstanceOf[String] val partition = key.get(KEY_PARTITION_FIELD).asInstanceOf[Int] GroupTopicPartition(group, TopicAndPartition(topic, partition)) } /** * Decodes the offset messages' payload and retrieves offset and metadata from it * * @param buffer input byte-buffer * @return an offset-metadata object from the message */ private def readMessageValue(buffer: ByteBuffer): OffsetAndMetadata = { val structAndVersion = readMessageValueStruct(buffer) if (structAndVersion.value == null) { // tombstone null } else { if (structAndVersion.version == 0) { val offset = structAndVersion.value.get(VALUE_OFFSET_FIELD_V0).asInstanceOf[Long] val metadata = structAndVersion.value.get(VALUE_METADATA_FIELD_V0).asInstanceOf[String] val timestamp = structAndVersion.value.get(VALUE_TIMESTAMP_FIELD_V0).asInstanceOf[Long] OffsetAndMetadata(offset, metadata, timestamp) } else if (structAndVersion.version == 1) { val offset = structAndVersion.value.get(VALUE_OFFSET_FIELD_V1).asInstanceOf[Long] val metadata = structAndVersion.value.get(VALUE_METADATA_FIELD_V1).asInstanceOf[String] val commitTimestamp = structAndVersion.value.get(VALUE_COMMIT_TIMESTAMP_FIELD_V1).asInstanceOf[Long] // not supported in 0.8.2 // val expireTimestamp = structAndVersion.value.get(VALUE_EXPIRE_TIMESTAMP_FIELD_V1).asInstanceOf[Long] OffsetAndMetadata(offset, metadata, commitTimestamp) } else if (structAndVersion.version == 2) { val offset = structAndVersion.value.get(VALUE_OFFSET_FIELD_V2).asInstanceOf[Long] val metadata = structAndVersion.value.get(VALUE_METADATA_FIELD_V2).asInstanceOf[String] val commitTimestamp = structAndVersion.value.get(VALUE_COMMIT_TIMESTAMP_FIELD_V2).asInstanceOf[Long] // not supported in 0.8.2 // val expireTimestamp = structAndVersion.value.get(VALUE_EXPIRE_TIMESTAMP_FIELD_V1).asInstanceOf[Long] OffsetAndMetadata(offset, metadata, commitTimestamp) }else if(structAndVersion.version == 3){ val offset = structAndVersion.value.get(VALUE_OFFSET_FIELD_V3).asInstanceOf[Long] val metadata = structAndVersion.value.get(VALUE_METADATA_FIELD_V3).asInstanceOf[String] val commitTimestamp = structAndVersion.value.get(VALUE_COMMIT_TIMESTAMP_FIELD_V3).asInstanceOf[Long] // not supported in 0.8.2 // val expireTimestamp = structAndVersion.value.get(VALUE_EXPIRE_TIMESTAMP_FIELD_V1).asInstanceOf[Long] OffsetAndMetadata(offset, metadata, commitTimestamp) } else { throw new IllegalStateException("Unknown offset message version: " + structAndVersion.version) } } } private def readMessageValueStruct(buffer: ByteBuffer): MessageValueStructAndVersion = { if(buffer == null) { // tombstone MessageValueStructAndVersion(null, -1) } else { val version = buffer.getShort() val valueSchema = schemaFor(version).valueSchema val value = valueSchema.read(buffer).asInstanceOf[Struct] MessageValueStructAndVersion(value, version) } } }解决了吗?同错
请问大佬,消费者端会维护一个offset吗?
维护一个?没懂你的意思额。
broker会维护offset。消费者在消费消息时,会在本地保存offset,在提交给服务端吗?
反过来的,offset是由消费者自己维护的,只是存储在了服务端中。
这样的话,消费者在处理完消息后,提交offset失败,再消费应该会重复消费吧?
是的。
谢谢大佬,要是消费端能处理成功后存个offset记录,应该能避免这种重复消费了
存在消费者本地
不用的,你可以手动控制提交offset。你业务成功后,在提交offset就行了。
我前面是说业务处理成功了,提交那步出了问题,这就没办法了,然后服务端不会更新offset,如果本地也有维护备份offset的话,下次消费就可以对比获取到的消息中的offset,选择处理未消费部分
好吧,我们生产用了4年,先提交offset,然后处理业务,如果业务重的,我就降低了并发,提交offset的数量控制了,保证即使项目崩溃也丢不了几条消息(项目直接崩溃4年来没遇到过,也就是说从没丢过消息),只要是正常的关闭,都不会有问题。
嗯嗯,我前面想的也有问题,如果消费者重试提交有问题的话,消费组应该会把这个消费端抛弃掉再平衡,大佬,你们有把卡夫卡用在涉及到资金的交易里面吗,比如支付类的,感觉这种交易错一次都会被投诉…
https://www.orchome.com/1056
这个额,我早年写的。
不能发表情。
哈哈哈,嗯,好的,感谢大佬赐教,早点休息!