环境搭建好之后,您一定迫不及待地想试试深度学习的程序了吧。本章就直接将一个例子拿出来,在没有任何基础的前提下,一步一步实现一个简单的神经网络。通过这个实例来理解模型,并了解TensorFlow开发的基本步骤。
从一组看似混乱的数据中找出y≈2x的规律
通过一个简单的逻辑回归实例为读者展示深度学习的神奇。通过对代码的具体步骤,让您对深度学习有一个直观的印象。
实例描述
假设有一组数据集,其x和y的对应关系为y≈2x。这个例子就是让神经网络学习这些样本,并能够找到其中的规律,即让神经网络能够总结出y≈2x这样的公式。
深度学习大概有如下4个步骤:
- 准备数据。
- 搭建模型。
- 迭代训练。
- 使用模型。
准备数据阶段一般就是把任务的相关数据收集起来,然后建立网络模型,通过一定的迭代训练让网络学习到收集来的数据特征,形成可用的模型,之后就是使用模型来为我们解决问题。
1、准备数据
这里使用y=2x这个公式来做主体,通过加入一些干扰噪声让它的"等号"变成"约等于"。
具体代码如下:
01 import tensorflow as tf
02 import numpy as np
03 import matplotlib.pyplot as plt
04
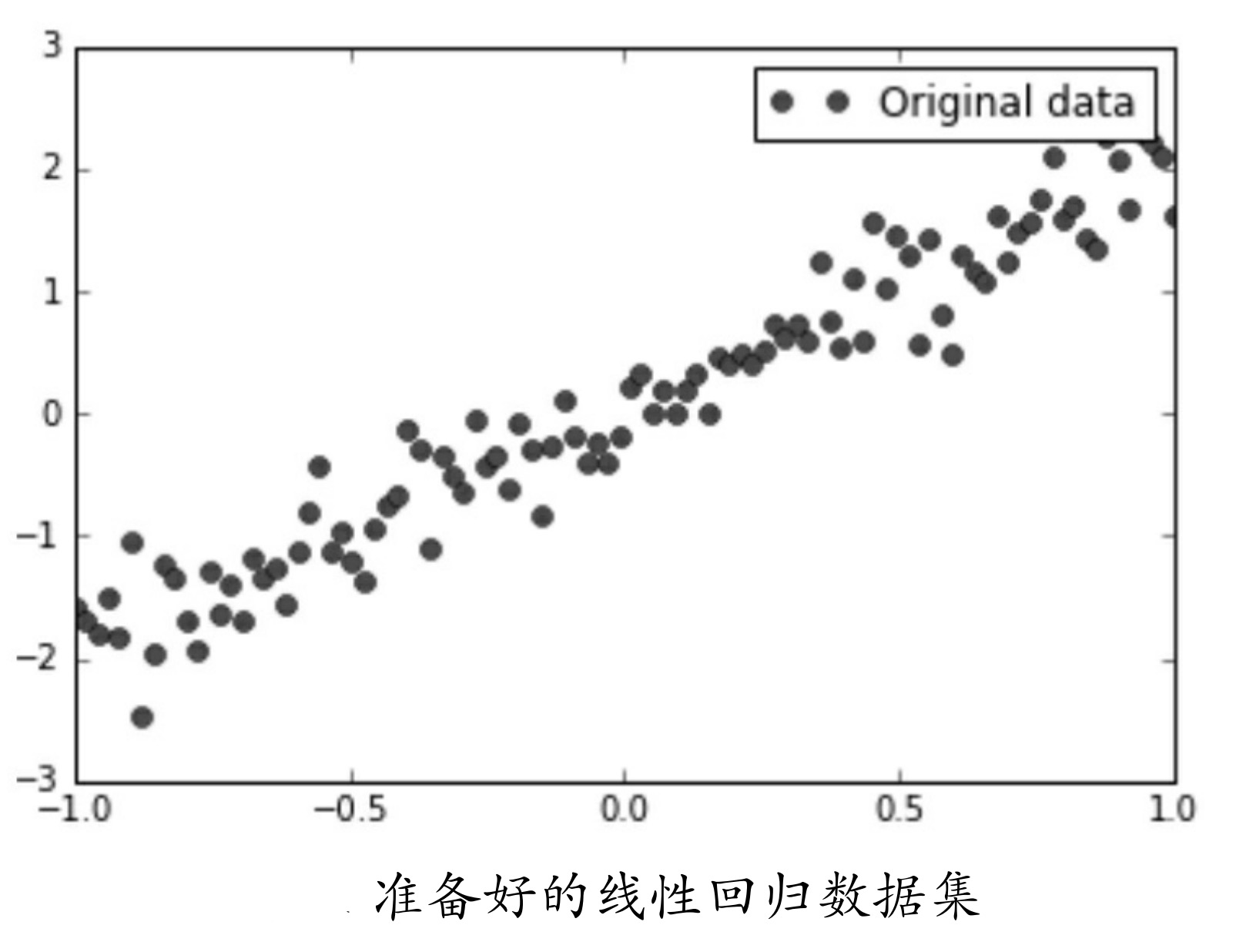
05 train_X = np.linspace(-1, 1, 100) # 生成-1到1的100个随机数
06 train_Y = 2 * train_X + np.random.randn(*train_X.shape) * 0.3 # y=2x,但是加入了噪声 y=2x+a*0.3 (a属于[-1,1]之间的随机数)
07 # 显示模拟数据点
08 plt.plot(train_X, train_Y, 'ro', label='Original data')
09 plt.legend()
10 plt.show()
- 导入头文件,然后生成-1~1之间的100个数作为x,见代码第1~5行。
- 将x乘以2,再加上一个[-1,1]区间的随机数×0.3。即,
y= 2×x + a×0.3(a属于[-1,1]之间的随机数),见代码第6行。
注意:
np.random.randn(*train_X.shape这个代码看起来比较奇怪,现在给出解释—它等同于np.random. randn(100)
运行上面代码,显示如下。
2、搭建模型
现在开始进行模型搭建。模型分为两个方向:正向和反向。
1.正向搭建模型
(1)了解模型及其公式
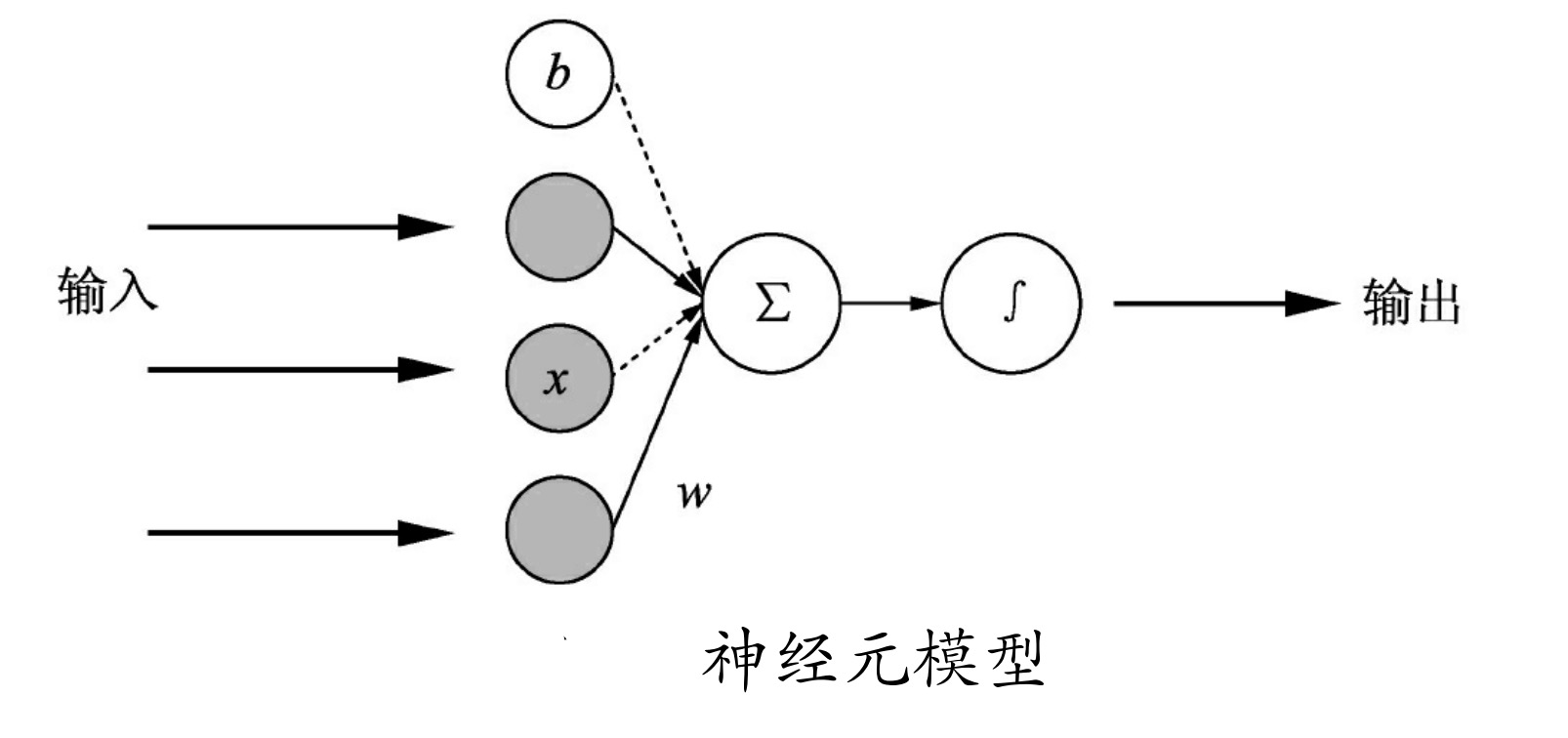
在具体操作之前,先来了解一下模型的样子。神经网络是由多个神经元组成的,单个神经元的网络模型如图所示。
其计算公式:
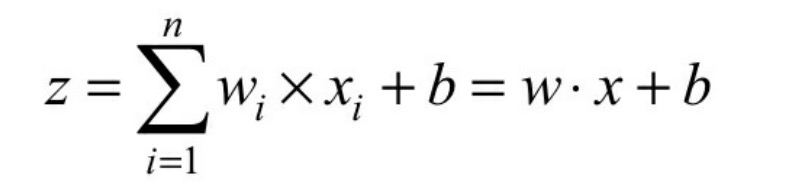
式中,z为输出的结果,x为输入,w为权重,b为偏执值。
z的计算过程是将输入的x与其对应的w相乘,然后再把结果相加上偏执b。
例如,有3个输入x1 ,x2 ,x3 ,分别对应w1,w2 ,w3 ,则,z = x1×w1 + x2×w2 + x3×w3 +b。这一过程中,在线性代数中正好可以用两个矩阵来表示,于是就可以写成(矩阵W)×(矩阵X)+b。矩阵相乘的展开如式:

上面的算式表明:形状为1行3列的矩阵与3行1列的矩阵相乘,结果的形状为1行1列的矩阵,即(1,3)×(3,1)=(1,1)
注意: 这里有个小窍门,如果想得到两个矩阵相乘后的形状,可以将第一个矩阵的行与第二个矩阵的列组合起来,就是相乘后的形状。
在神经元中,w和b可以理解为两个变量。模型每次的“学习”都是调整w和b以得到一个更合适的值。最终,有这个值配合上运算公式所形成的逻辑就是神经网络的模型。
(2)创建模型
下面的代码演示了如何创建图中的模型。
11 # 创建模型
12 # 占位符
13 X = tf.placeholder("float")
14 Y = tf.placeholder("float")
15 # 模型参数
16 W = tf.Variable(tf.random_normal([1]), name="weight")
17 b = tf.Variable(tf.zeros([1]), name="bias")
18 # 前向结构
19 z = tf.multiply(X, W)+ b
- X和Y:为占位符,使用了placeholder函数进行定义。一个代表x的输入,一个代表对应的真实值y。
- W和b:就是前面说的参数。W被初始化成[-1,1]的随机数,形状为一维的数字,b的初始化为0,形状也是一维的数字。
- Variable:定义变量。
- tf.multiply:是两个数相乘的意思,结果再加上b就等于z了。
2.反向搭建模型
神经网络在训练的过程中数据的流向有两个方向,即先通过正向生成一个值,然后观察其与真实值的差距,再通过反向过程将里面的参数进行调整,接着再次正向生成预测值并与真实值进行比对,这样循环下去,直到将参数调整为合适值为止。
正向相对比较好理解,反向传播会引入一些算法来实现对参数的正确调整。
下面先看一下反向优化的相关代码。
20 #反向优化
21 cost = tf.reduce_mean(tf.square(Y - z))
22 learning_rate = 0.01
23 optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost) #梯度下降
代码说明如下:
- 第21行定义一个cost,它等于生成值与真实值的平方差。
- 第22行定义一个学习率,代表调整参数的速度。这个值一般是小于1的。这个值越大,表明调整的速度越大,但不精确;值越小,表明调整的精度越高,但速度慢。这就好比生物课上的显微镜调试,显微镜上有两个调节焦距的旋转钮,分为粗调和细调。
- 第23行GradientDescentOptimizer函数是一个封装好的梯度下降算法,里面的参数learning_rate叫做学习率,用来指定参数调节的速度。如果将“学习率”比作显微镜上不同档位的“调节钮”,那么梯度下降算法也可以理解成“显微镜筒”,它会按照学习参数的速度来改变显微镜上焦距的大小。
3、迭代训练模型
迭代训练的代码分成两步来完成:
1.训练模型
建立好模型后,可以通过迭代来训练模型了。TensorFlow中的任务是通过session来进行的。
下面的代码中,先进行全局初始化,然后设置训练迭代的次数,启动session开始运行任务。
24 #初始化所有变量
25 init = tf.global_variables_initializer()
26 #定义参数
27 training_epochs = 20
28 display_step = 2
29
30 #启动session
31 with tf.Session() as sess:
32 sess.run(init)
33 plotdata={"batchsize":[],"loss":[]} #存放批次值和损失值
34 #向模型输入数据
35 for epoch in range(training_epochs):
36 for (x, y) in zip(train_X, train_Y):
37 sess.run(optimizer, feed_dict={X: x, Y: y})
38
39 #显示训练中的详细信息
40 if epoch % display_step == 0:
41 loss = sess.run(cost,feed_dict={X:train_X,Y:train_Y})
42 print ("Epoch:", epoch+1,"cost=", loss,"W=",sess.run(W),"b=", sess.run(b))
43 if not (loss == "NA" ):
44 plotdata["batchsize"].append(epoch)
45 plotdata["loss"].append(loss)
46
47 print (" Finished!")
48 print ("cost=", sess.run(cost, feed_dict={X: train_X, Y: train_Y}),"W=", sess.run(W), "b=", sess.run(b))
上面的代码中迭代次数设置为20次,通过sess.run来进行网络节点的运算,通过feed机制将真实数据灌到占位符对应的位置(feed_dict={X:x,Y: y}),同时,每执行一次都会将网络结构中的节点打印出来。
运行代码,输出信息如下:
Epoch: 1 cost= 0.714926 W= [ 0.71911603] b= [ 0.40933588]
Epoch: 3 cost= 0.114213 W= [ 1.63318455] b= [ 0.17000227]
Epoch: 5 cost= 0.0661118 W= [ 1.88165665] b= [ 0.0765276]
Epoch: 7 cost= 0.0633376 W= [ 1.94610846] b= [ 0.05182607]
Epoch: 9 cost= 0.0632785 W= [ 1.96277654] b= [ 0.0454303]
Epoch: 11 cost= 0.0633072 W= [ 1.96708632] b= [ 0.04377643]
Epoch: 13 cost= 0.0633176 W= [ 1.96820116] b= [ 0.04334867]
Epoch: 15 cost= 0.0633205 W= [ 1.96848941] b= [ 0.04323809]
Epoch: 17 cost= 0.0633212 W= [ 1.9685632] b= [ 0.04320973]
Epoch: 19 cost= 0.0633214 W= [ 1.96858287] b= [ 0.04320224]
Finished!
cost= 0.0633215 W= [ 1.96858633] b= [ 0.04320095]
可以看出,cost的值在不断地变小,w和b的值也在不断地调整。
2.训练模型可视化
上面的数值信息理解起来还是比较抽象。为了可以得到更直观的表达,下面将模型中的两个信息可视化出来,一个是生成的模型,另一个是训练中的状态值。具体代码如下:
49 #图形显示
50 plt.plot(train_X, train_Y, 'ro', label='Original data')
51 plt.plot(train_X, sess.run(W) * train_X + sess.run(b), label='Fittedline')
52 plt.legend()
53 plt.show()
54
55 plotdata["avgloss"] = moving_average(plotdata["loss"])
56 plt.figure(1)
57 plt.subplot(211)
58 plt.plot(plotdata["batchsize"], plotdata["avgloss"], 'b--')
59 plt.xlabel('Minibatch number')
60 plt.ylabel('Loss')
61 plt.title('Minibatch run vs. Training loss')
62
63 plt.show()
这段代码中引入了一个变量和一个函数,可以在代码的最顶端定义它们,见如下代码:
plotdata = {"batchsize": [], "loss": []}
def moving_average(a, w=10):
if len(a) < w:
return a[:]
return [val if idx < w else sum(a[(idx - w):idx]) / w for idx, val in enumerate(a)]
现在所有的代码都准备好了,运行程序,生成如下两幅图。
图1、可视化模型
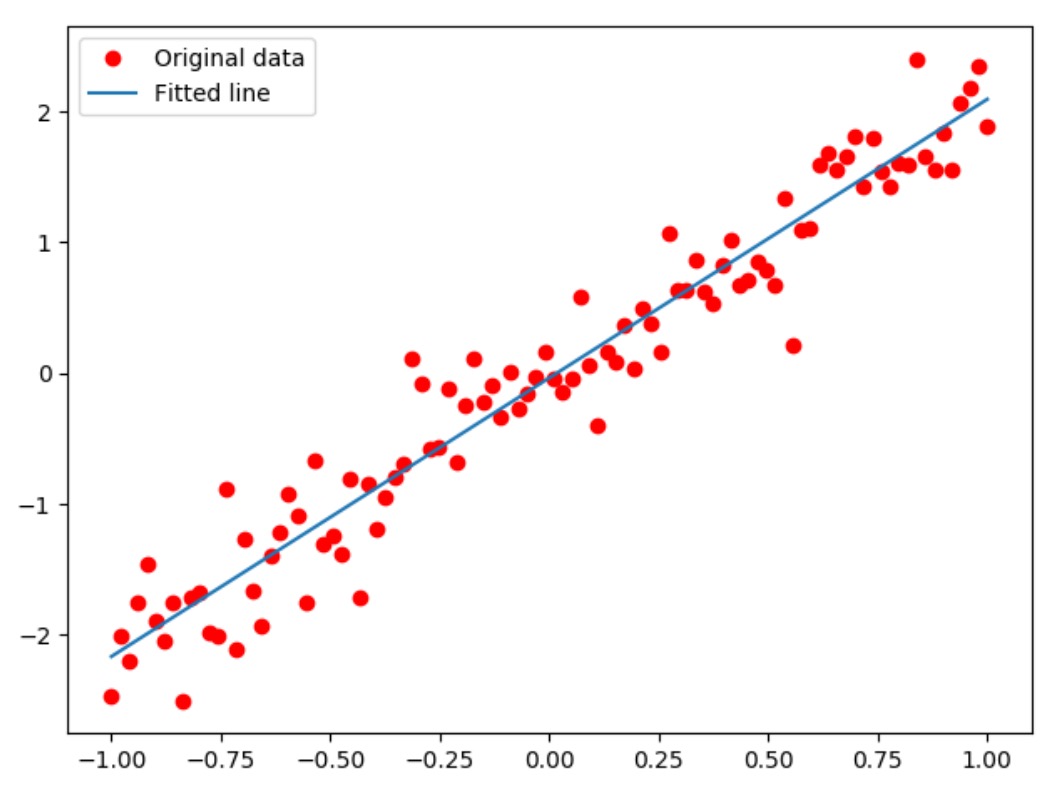
图2、可视化训练loss
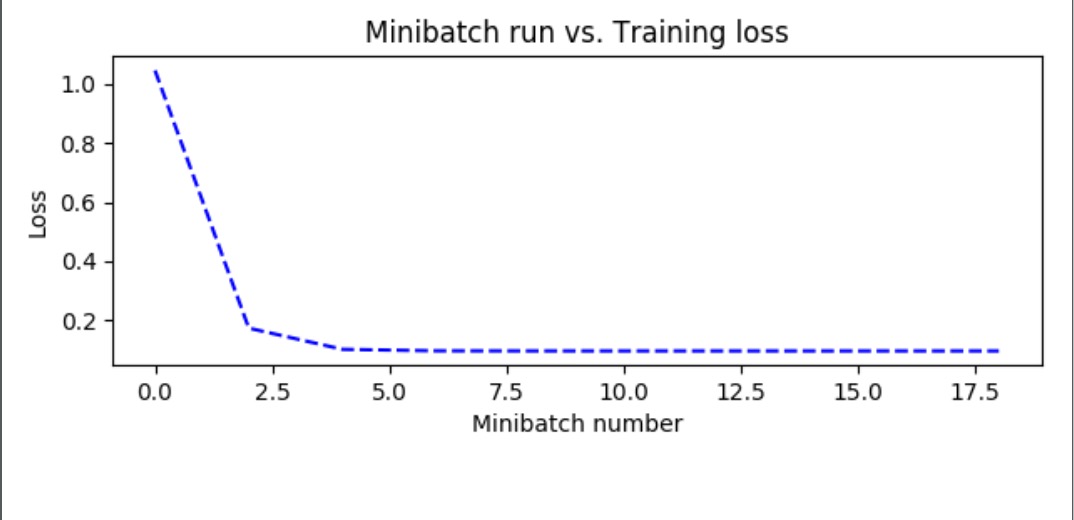
图中所示的
蓝色斜线,是模型中的参数w和b为常量所组成的关于x与y的直线方程。可以看到是一条几乎y=2x的直线(W=1.96858633接近于2,b=0.04320095接近于0)。在图中可以看到刚开始损失值一直在下降,直到6次左右趋近平稳。
4、使用模型
模型训练好后,用起来就比较容易了,往里面传一个0.2(通过feed_dict={X:0.2}),然后使用sess.run来运行模型中的z节点,见如下代码,看看它生成的值。
print ("x=0.2,z=", sess.run(z, feed_dict={X: 0.2}))
将上述代码加到代码文件“3-1线性回归.py”的最后一行,运行后可以得到如下信息:
x=0.2,z= [ 0.4324449]
训练好的模型,可以根据已有数据的规律推算出输入值0.2对应的z值。
注意: 您在自己的计算机上运行该程序,得到的z值与书上的会不一样。这是因为b和w不一样。神经网络学习的是一种规律,能表示这一种规律的b和w会有很多值,即模型学出来的并非是唯一值。


