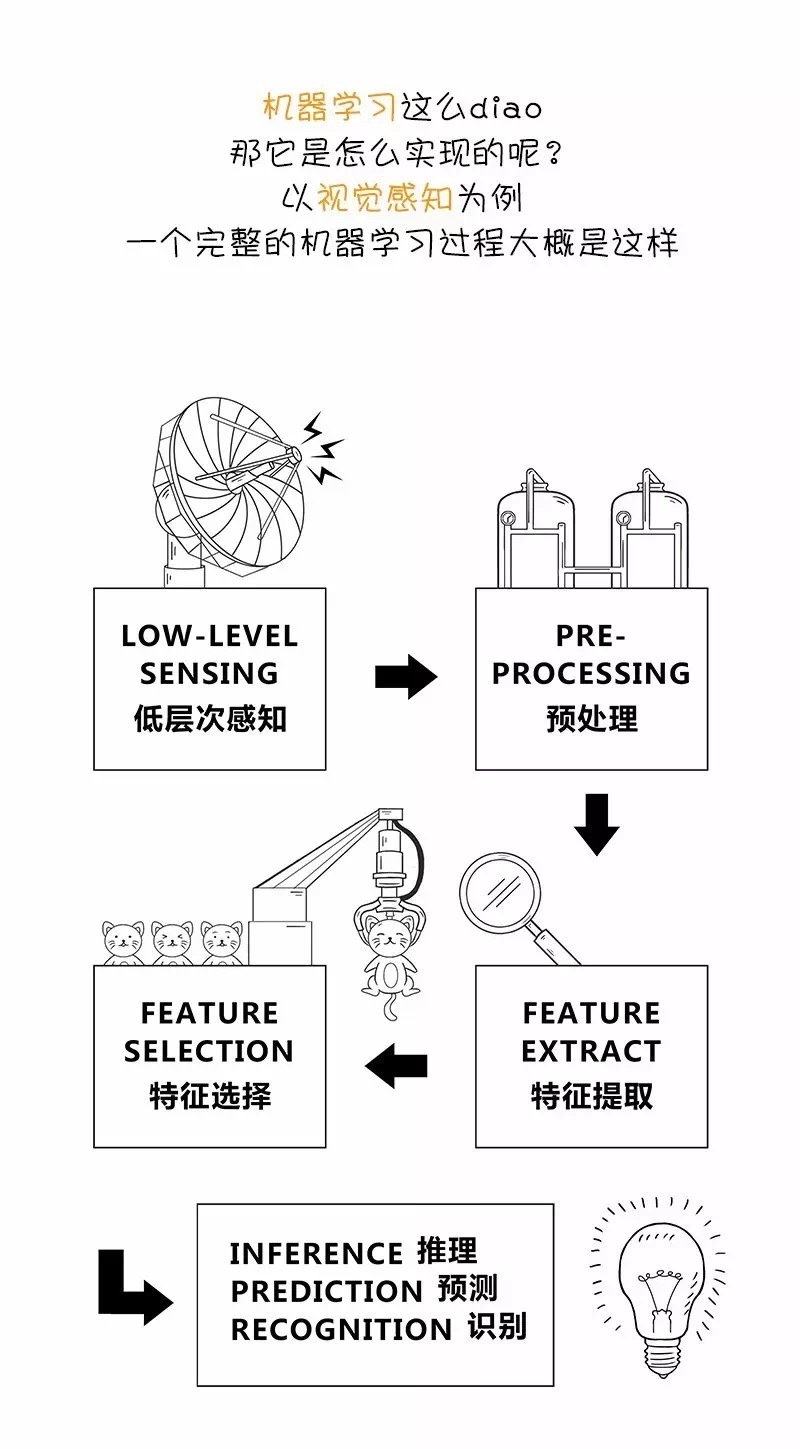
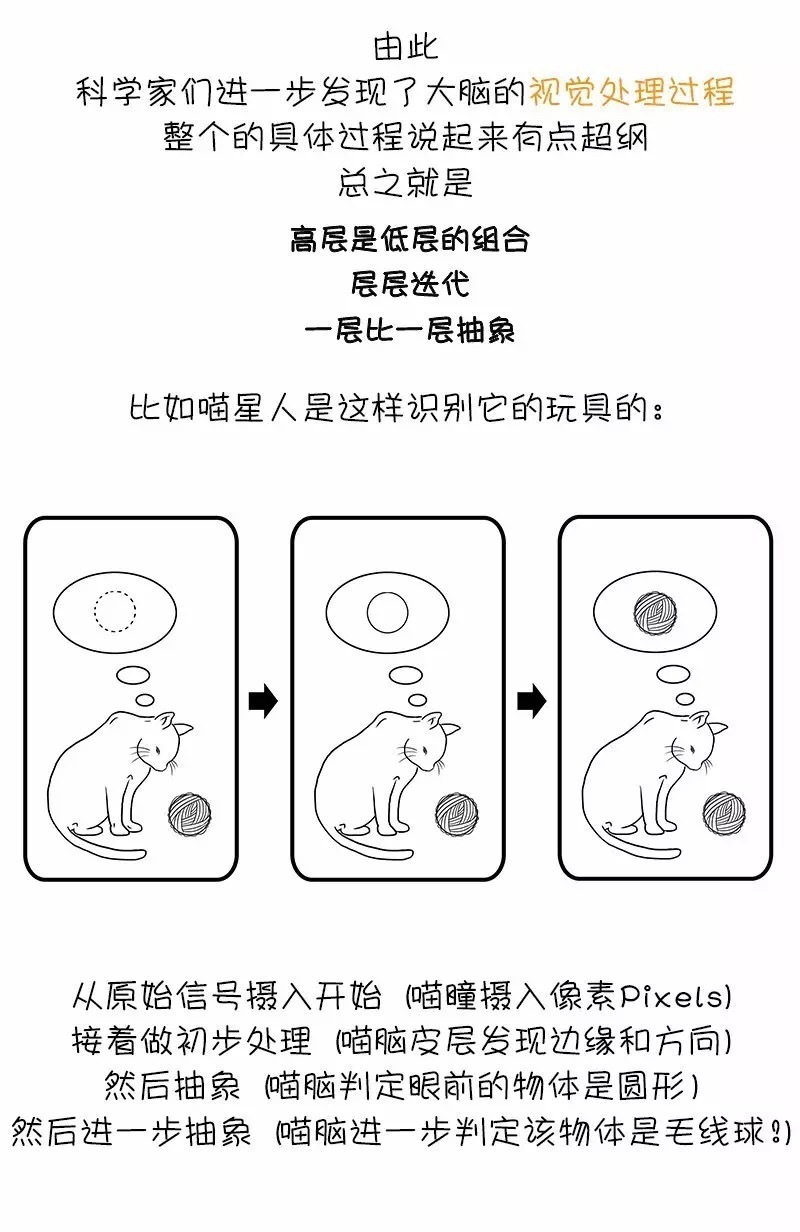
要说当下科技圈最炙手可热的词汇,一定非“人工智能”莫属:人工智能(Artificial Intelligence)、机器学习(Machine Learning)、深度学习(Deep Learning)。不少人对这些高频词汇的含义及其背后的关系总是似懂非懂的。
此文用最简单的语言解释了这些词汇的含义,理清它们之间的关系,希望对刚入门的同学有所帮助。
人工智能(Artificial Intelligence)——为机器赋予人的智能
先说“人工智能”,也就是 AI。“人工智能”一词最早由认知科学家约翰·麦卡锡在研究中提出,他写到,“这项研究基于一种推测,即任何学习行为或其它智力特征,在原则上都可以被精确地描述,从而可以制造出一台机器来模拟它。
从广义上讲,“人工智能”描述一种机器与周围世界交互的各种方式。通过软件和硬件的结合——一台“人工智能”设备可以模仿人类的行为或像人一样执行任务。
举个例子,假如你手机里存了你女朋友和你的照片,你想把它们区分开,这时就可以把任务交给“人工智能”,在分辨人脸这类应用中,“人工智能”能比人更高效地执行任务。正因为此,“人工智能”目前也被应用到了许多其他领域,从计算机视觉和自然语言处理,到各种终端。

如上图,配备人工智能的机器会模仿人类的思维过程,具备分辨苹果和橙子的能力。
但它们是如何实现的?这种智能是从何而来?这就带我们来到同心圆的里面一层,机器学习了。
机器学习—— 一种实现人工智能的方法
随着人对计算机科学的期望越来越高,要求它解决的问题越来越复杂,已经远远不能满足人们的诉求了。于是有人提出了一个新的思路 -- 能否不为难码农,让机器自己去学习呢?
机器学习就是用算法解析数据,不断学习,对世界中发生的事做出判断和预测的一项技术。研究人员不会亲手编写软件、确定特殊指令集、然后让程序完成特殊任务;而是会用大量数据和算法来“训练”机器,让机器学会如何执行任务。
这里有三个重要的信息:
- “机器学习”是“模拟、延伸和扩展人的智能”的一条路径,所以是人工智能的一个子集;
- “机器学习”是要基于大量数据的,也就是说它的“智能”是用大量数据喂出来的;
- 正是因为要处理海量数据,所以大数据技术尤为重要;“机器学习”只是大数据技术上的一个应用。常用的10大机器学习算法有:决策树、随机森林、逻辑回归、SVM、朴素贝叶斯、K最近邻算法、K均值算法、Adaboost算法、神经网络、马尔科夫。
深度学习:一种实现机器学习的技术
“深度学习”作为近十年来人工智能领域取得的重大突破,推动了计算机智能取得长足进步。它用大量的数据和计算能力来模拟深度神经网络。从本质上说,这些网络模仿人类大脑的连通性,对数据集进行分类,并发现它们之间的相关性。
还是以识别女朋友和老妈为例,深度学习的工作就是自动分析图像中人物的年龄、表情、姿态等信息,这过程中不需要人的参与,而传统的机器学习算法,往往需要人工调整参数,因此参数的数量十分有限,而“深度学习”可以从大数据中自动获得成千上万的参数。
追加一些重点:
人工神经网络(Artificial Neural Networks)是早期机器学习中的一个重要的算法,历经数十年。神经网络的原理是受我们大脑的生理结构——互相交叉相连的神经元启发。但与大脑中一个神经元可以连接一定距离内的任意神经元不同,人工神经网络具有离散的层、连接和数据传播的方向。
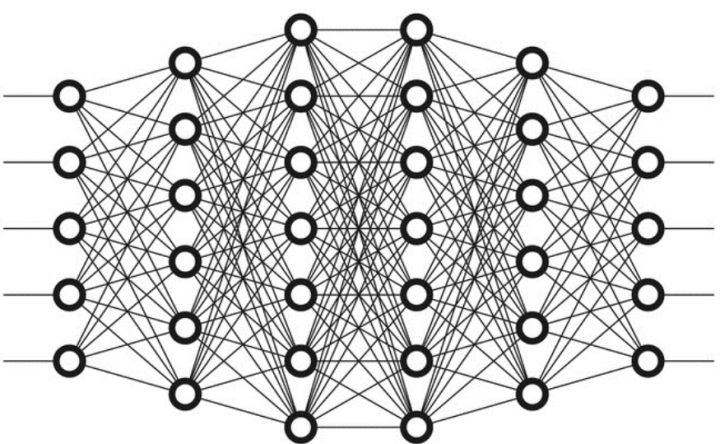
例如,我们可以把一幅图像切分成图像块,输入到神经网络的第一层。在第一层的每一个神经元都把数据传递到第二层。第二层的神经元也是完成类似的工作,把数据传递到第三层,以此类推,直到最后一层,然后生成结果。
每一个神经元都为它的输入分配权重,这个权重的正确与否与其执行的任务直接相关。最终的输出由这些权重加总来决定。
我们以停止(Stop)标志牌为例。将一个停止标志牌图像的所有元素都打碎,然后用神经元进行“检查”:八边形的外形、救火车般的红颜色、鲜明突出的字母、交通标志的典型尺寸和静止不动运动特性等等。神经网络的任务就是给出结论,它到底是不是一个停止标志牌。神经网络会根据所有权重,给出一个经过深思熟虑的猜测——“概率向量”。
这个例子里,系统可能会给出这样的结果:86%可能是一个停止标志牌;7%的可能是一个限速标志牌;5%的可能是一个风筝挂在树上等等。然后网络结构告知神经网络,它的结论是否正确。
其实在人工智能出现的早期,神经网络就已经存在了,但神经网络对于“智能”的贡献微乎其微。主要问题是,即使是最基本的神经网络,需要大量的运算。神经网络算法的运算需求难以得到满足。
不过,还是有一些虔诚的研究团队,坚持研究,实现了以超算为目标的并行算法的运行与概念证明。但也直到GPU得到广泛应用,这些努力才见到成效。
我们回过头来看这个停止标志识别的例子。神经网络是调制、训练出来的,时不时还是很容易出错的。它最需要的,就是训练。需要成百上千甚至几百万张图像来训练,直到神经元的输入的权值都被调制得十分精确,无论是否有雾,晴天还是雨天,每次都能得到正确的结果。
只有这个时候,我们才可以说神经网络成功地自学习到一个停止标志的样子;
在Facebook的应用里,神经网络自学习了你妈妈的脸。
现在,经过深度学习训练的图像识别,在一些场景中甚至可以比人做得更好:从识别猫,到辨别血液中癌症的早期成分,到识别核磁共振成像中的肿瘤。Google的AlphaGo先是学会了如何下围棋,然后与它自己下棋训练。它训练自己神经网络的方法,就是不断地与自己下棋,反复地下,永不停歇。
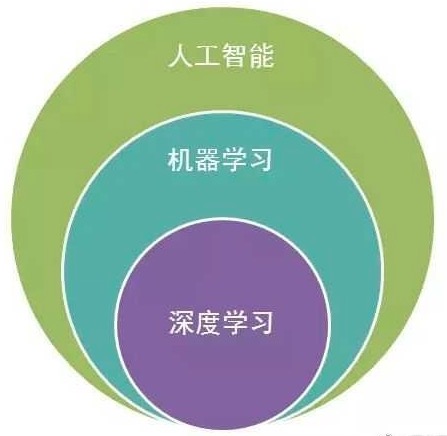
总结
用一个网上的一张图来总结一下吧。