无论使用哪种存储方式(对象,块,文件),存储的数据当底层保存时,都会被切分成一个个大小固定的对象(Objects),对象大小可以由管理员自定义调整,RADOS中基本的存储单位就是Objects,一般为2MB或4MB(最后一个对象大小有可能不同)。
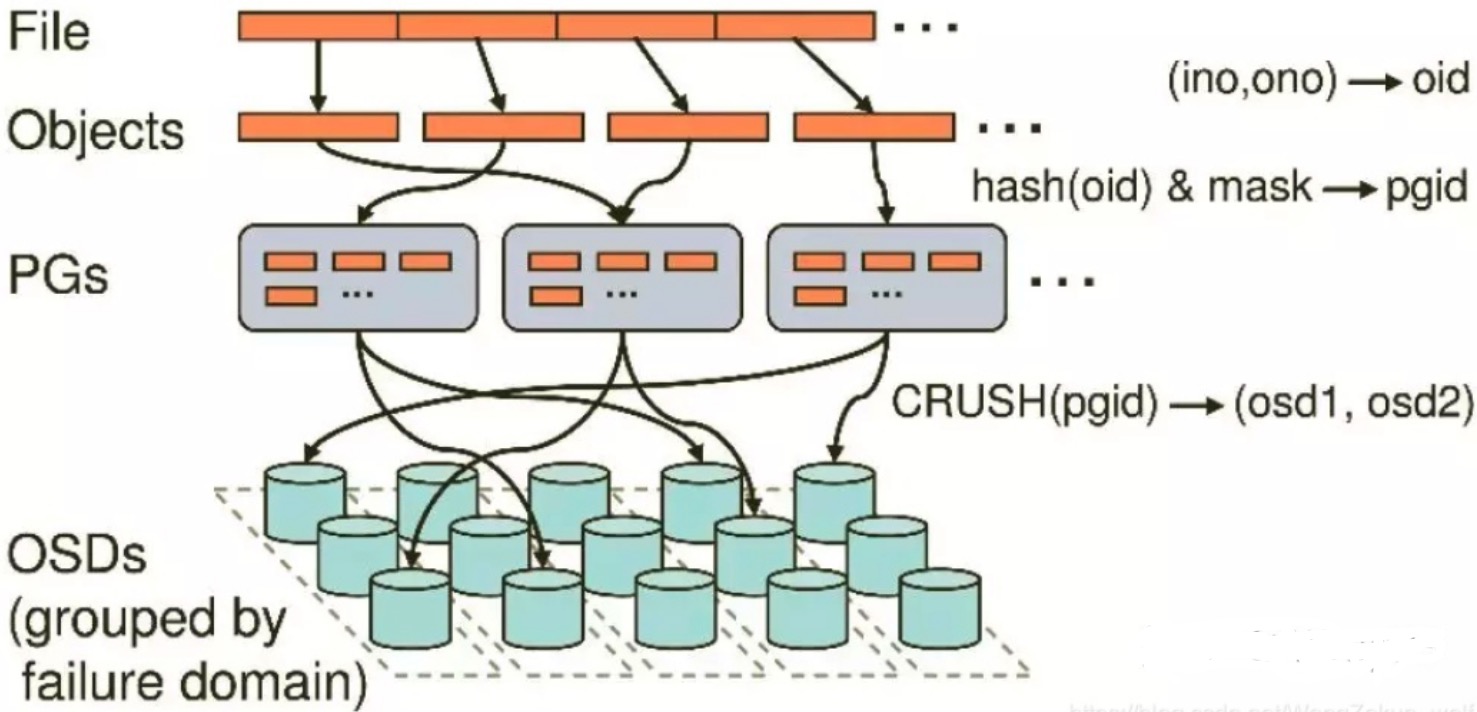
一个个文件(File)被切割成大小固定的Objects后,将这些对象分配到一个PG(Placement Group)中,然后PG会通过多副本的方式复制几份,随机分派给不同的存储节点(也可指定)。
当新的存储节点(OSD)被加入集群后,会在已有数据中随机抽取一部分数据迁移到新节点,这种概率平衡的分布方式可以保证设备在潜在的高负载下正常工作,更重要的事,数据的分布过程仅需要做几次随机映射,不需要大型的集中式分配表,方便且快速,不会对集群产生大的影响。
各层说明
File:用户需要存储或者访问的文件。
Objects:RADOS的基本存储单元,即对象。Object与上面提到的file的区别是,object的最大size由RADOS限定(通常为2MB或4MB),以便实现底层存储的组织管理。以便实现底层存储的组织管理。因此,当上层应用向RADOS存入size很大的file时,需要将file切分成统一大小的一系列object进行存储。
PG(Placement Group):直译过来即为放置组,所以这里PG作用是对object的存储进行组织和位置映射,它是一个逻辑概念,在Linux系统中可以直接看到对象,但是无法直接看到PG,它在数据寻址中类似于数据库中的索引。用来放置若干个object(可以数千个甚至更多),但一个object只能被映射到一个PG中,即,PG和object之间是“一对多”的映射关系。同时,一个PG会被映射到n个OSD上,而每个OSD上都会承载大量的PG,即,PG和OSD之间是 “多对多” 映射关系。在实践当中,n至少为2(n代表冗余的份数),如果用于生产环境,则至少为3。一个OSD上的PG则可达到数百个。
OSD(Object Storage Daemon):通过管理 OSD 来管理物理硬盘。负责处理集群数据的复制、恢复、回填、再均衡,并向其他osd守护进程发送心跳,然后向Mon提供一些监控信息。当Ceph存储集群设定数据有两个副本时(一共存两份),则至少需要三个OSD守护进程即三个OSD节点,集群才能达到active+clean状态,实现冗余和高可用。
oid 每个object都会有一个唯一的OID,由ino和ono生成。ino即文件的File ID,用于在全局唯一标识每一个文件,ono则是分片编号(对象编号)。例如:一个文件FileID为A,被切割为对象编号是A0,A1的两个对象。
pgid 使用静态hash函数对OID做hash去除特征码,用特征码与PG的数量去模,得到的序号即是PGID,由于这种设计方式,所以PG数量的多少会直接决定了数据分布的均匀性,所以需要合理设置PG的数量可以很好的提升CEPH集群的性能并使数据均匀分布。
存储过程中各层次之间的映射关系:
file -> object
object的最大size是由RADOS配置的,当用户要存储一个file,需要将file切分成若干个object。object -> PG
每个object都会被映射到一个PG中,然后以PG为单位进行副本备份以及进一步映射到具体的OSD上。PG -> OSD
通过CRUSH算法来实现,根据用户设置的冗余存储的个数r,PG会最终存储到r个OSD上。
存储过程具体说明:
用户通过客户端存储一个文件时,在RAODS中,该File(文件)会被分割为多个2MB/4MB大小的 Objects(对象)。而每个文件都会有一个文件ID,例如A,那么这些对象的ID就是A0,A1,A2等等。然而在分布式存储系统中,有成千上万个对象,只是遍历就要花很久时间,所以对象会先通过hash-取模运算,存放到一个PG中。
PG相当于数据库的索引(PG的数量是固定的,不会随着OSD的增加或者删除而改变),这样只需要首先定位到PG位置,然后在PG中查询对象即可。之后PG中的对象又会根据设置的副本数量进行复制,并根据CRUSH算法存储到OSD节点上。
为什么引入PG概念?
因为Object对象的size很小,并不会直接存储进OSD中,在一个大规模的集群中可能会存在几百到几千万个对象,这么多对象如果遍历寻址,那速度是很缓慢的,并且如果将对象直接通过某种固定映射的哈希算法映射到osd上,那么当这个osd损坏时,对象就无法自动迁移到其他osd上(因为映射函数不允许)。为了解决这些问题,ceph便引入了归置组的概念,即PG。
最后PG会根据管理设置的副本数量进行副本级别的复制,然后通过CRUSH算法存储到不同的osd上(其实是把PG中的所有对象存储到节点上),第一个osd节点即为主节点,其余均为从节点。
PG数量设置多少才合适?
根据以上所述,我们知道了pg数量的多少,会影响到集群的存储分布,以及集群存储的性能,那到底该如何规划pg数呢?我们首先来简单了解下PG-Pool的概念
Pool: 是ceph存储数据时的逻辑分区,它起到namespace的作用。每个pool包含一定数量(可配置) 的PG。PG里的对象被映射到不同的Object上。pool是分布到整个集群的。 pool可以做故障隔离域,根据不同的用户场景不统一进行隔离。
支持两种类型:副本(replicated)和 纠删码( Erasure Code)
副本(replicated):即复制,例如三副本,即为该Pool内的PG会复制三份纠删码(Erasure Code):是一种编码容错技术,其基本原理就是把传输的信号分段,加入一定的校验再让各段间发生相互关联,即使在传输过程中丢失部分信号,接收端仍然能通过算法将完整的信息计算出来。在数据存储中,纠删码将数据分割成片段,把冗余数据块扩展和编码,并将其存储在不同的位置,比如磁盘、存储节点或者其他地理位置。用更少的空间实现存储,即节约空间
pg 跟 pool 关联,一个pool有多少个pg,跟osd数相关
Ceph官方给的计算方式为:https://ceph.com/pgcalc/
根据以下的官方介绍,结合自身集群的规模大小(OSD多少)去计算合理的PG数
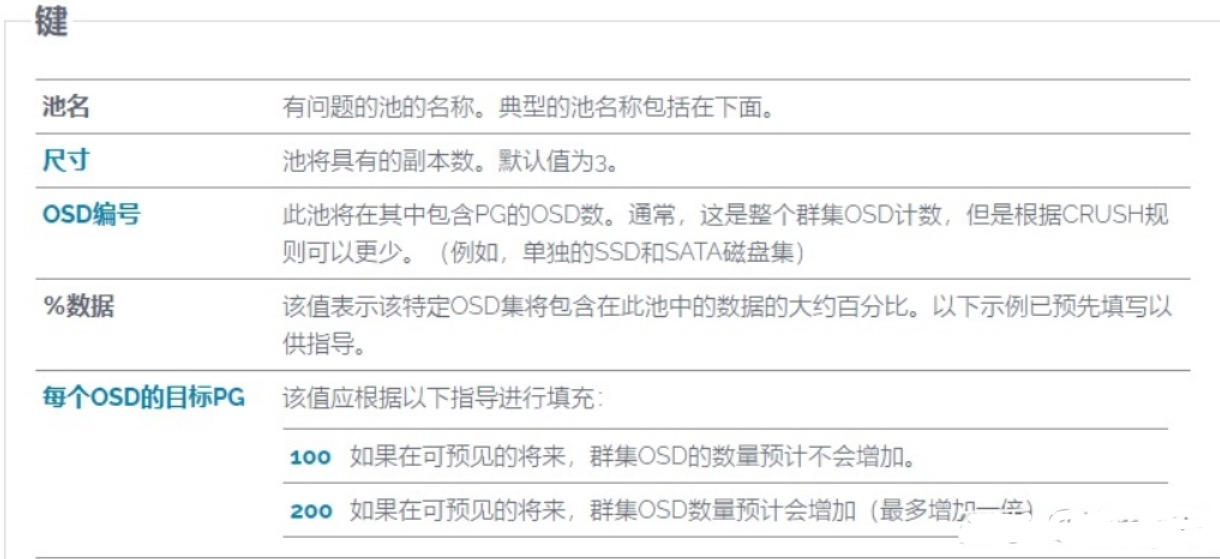

例如,上图,
使用3副本模式;OSD编号为5,即集群中5个OSD(硬盘);数据存储使用量为80%;在可以预见的未来,集群OSD数量不会增加。
根据官方计算出:
5 个 osd 时,设置128个pg。
10个 osd 时,设置256个pg。
100个 osd 时,设置2048个pg。
注: 一旦设置pg和pgp数量,最好就不需要再调整,否则会引发数据的大量迁移。如果一定要调整,请确保调整前,集群是ok状态;
严格意义上来说,我们无论为池分配多少个 pg 都没有问题。但有时候 pg_num 配置小了集群状态会报错,配置大了也会报错。这不是因为这么配置不对,是因为有其它的参数在限制我们随意配置 pg_num。
和PG密切相关的PGP是什么?
这里需要特别说明的是和PG相关的一个概念为PGP,我理解来PGP是用来放置PG使用的,PGP中包含了PG,Pool池中有多少个PG,就又多少个PGP,所以集群设置PG数量时,PGP也是同样的大小。
应该可以简单粗暴的如下图去理解

详细点来说:
pg_num(pg的数量): pg_num增加时,会导致原来各PG中的对象均匀的分布到新建PG中,但是原PG的实际物理存储位置不会发生变化,只是会影响这些PG所在的同一个Pool池中的object分布
pgp_num(pgp的数量): pgp_num增加时,因为PG是存在于PGP中,所以会导致PG的分布方式发生变化,但是PG内的对象并不会变动,只是会导致一些PG的实际物理存储位置发生变化。


