本次etcd 3.4版本主要在稳定性、性能、易操作性、投票前和无权投票成员以及存储后端和客户端平衡的重大改进。
存储后端的改进
etcd v3.4版本包含了许多针对大规模Kubernetes工作负载的性能改进。
特别是,即使没有写入,etcd也会遇到大量并发读取事务的性能问题(例如: “read-only range request ... took too long to execute(只读范围的请求......执行时间太长)”)。 以前,即使没有等待的写入,存储后端等待写入提交操作也会阻塞读取事务。现在,提交不会阻塞读取,这将改善长时间运行的读取事务性能。
以前,持续长时间的读取事务会阻塞写入和即将进行的读取。我们通过对后端读取事务完全并行优化,使得长时间运行的读取的情况下,写入吞吐量增加了70%,P99写入延迟减少了90%。我们还在GCE上进行了Kubernetes 5000个节点可扩展性测试,并观察到了这些变化。例如,非阻塞读取事务现在将其用于压缩批次大小,可减少压缩期间的P99服务器请求延迟。在测试的最初阶段,有很多长时间运行的“LIST pods”,“POST clusterrolebindings”的P99延迟减少了97.4%。
在lease storage(租赁存储)方面做了更多的改进。我们通过更有效地存储租赁对象来增强租赁expire/revoke性能,并且通过当前租赁grant/revoke操作使租赁查找操作无需阻塞。etd v3.4引入lease checkpoint作为实验性功能,通过协商一致性来保持剩余的生存时间值。这确保了在leader选举后短期租赁对象不会自动更新。当生存时间值相对较大时,可以防止租赁对象堆积(例如,Kubernetes中的1小时TTL永不过期)。
改进 Raft 的投票过程
etcd实现了Raft一致性数据复制算法。Raft是一种基于leader协议。数据从leader复制到follower; follower将提议转发给leader,leader决定做什么或不做。 一旦得到集群中quorum(仲裁)的同意,leader就会持续并复制一个条目。 集群成员选出一名leader,所有其他成员成为follower。 当选的leader定期向其follwer发送心跳以保持其领导力,并通过每个follwer的响应来跟踪其状态。
最简单的方式是,当Raft leader接收到具有更高话语权的消息而没有任何进一步的集群范围的健康检查时,它会逐一向follwer发送。 但此行为可能会影响整个集群的可用性。
例如,一个不稳定的成员进出(或重新加入),并开始竞选。该成员以更高的话语权发送,忽略较低话语权的传入的消息。当leader收到这个更高话语权的消息时,它会恢复到follwer。
当在网络分区的情况下,这会变成灾难。每当分区节点重新获得其连接时,它可能会触发leader重新选举。为了解决这个问题,etcd Raft引入了一个具有投票前功能的新节点状态预候选人。预候选人首先询问其他服务器是否有足够的最新信息来获得选票。 只有获得多数票,它才能增加任期,开始选举。这个额外的步骤总体上提高了leader选举的稳定性(只要它保持与仲裁的连接,帮助leader保持稳定)。
同样,当重启节点没有及时收到leader心跳时(网络速度慢),触发leader选举,etcd的可用性也会受到影响。此前,在服务器重新启动时,etcd快速转发选举标记,只有一个标记用于leader选举。 例如,当选举超时为1秒时,follwer在开始选举之前仅等待leader 100毫秒。 不需要等待选举超时,从而加速初始服务器启动(选举在100毫秒内触发,而不是1秒)。提前选举时间对于具有较大选举超时的跨数据中心部署非常有用。然而,在大多数情况下,可用性比初始leader选举的速度更为关键。为了确保重新连接节点的更好可用性,etcd现在使用多个标记来优化之前的一个标记,这样leader就有更多的时间来预防中断性的重新启动。
Raft Non-Voting Member, Learner
成员资格重新配置的挑战在于,它常常导致仲裁规模(quorum size)的变化,这很容易导致集群不可用。即使仲裁规模不变,改变成员资格的集群也更有可能遇到其他潜在的问题。为了提高重构的可靠性和可信度,在etcd 3.4版本中引入了一种新的角色Learner(学习器)。
一个新的etcd成员在没有初始数据的情况下加入集群,请求来自leader的所有历史更新,直到它赶上leader的日志。这意味着leader的网络更有可能超载,阻塞或降低leader的心跳给follwer。在这种情况下,follwer可能会选举超时,并开始新的leader选举。也就是说,拥有新成员的集群更容易受到leader选举的影响。leader选举和随后向新成员的更新数据都容易导致集群不可用(参见图1)。
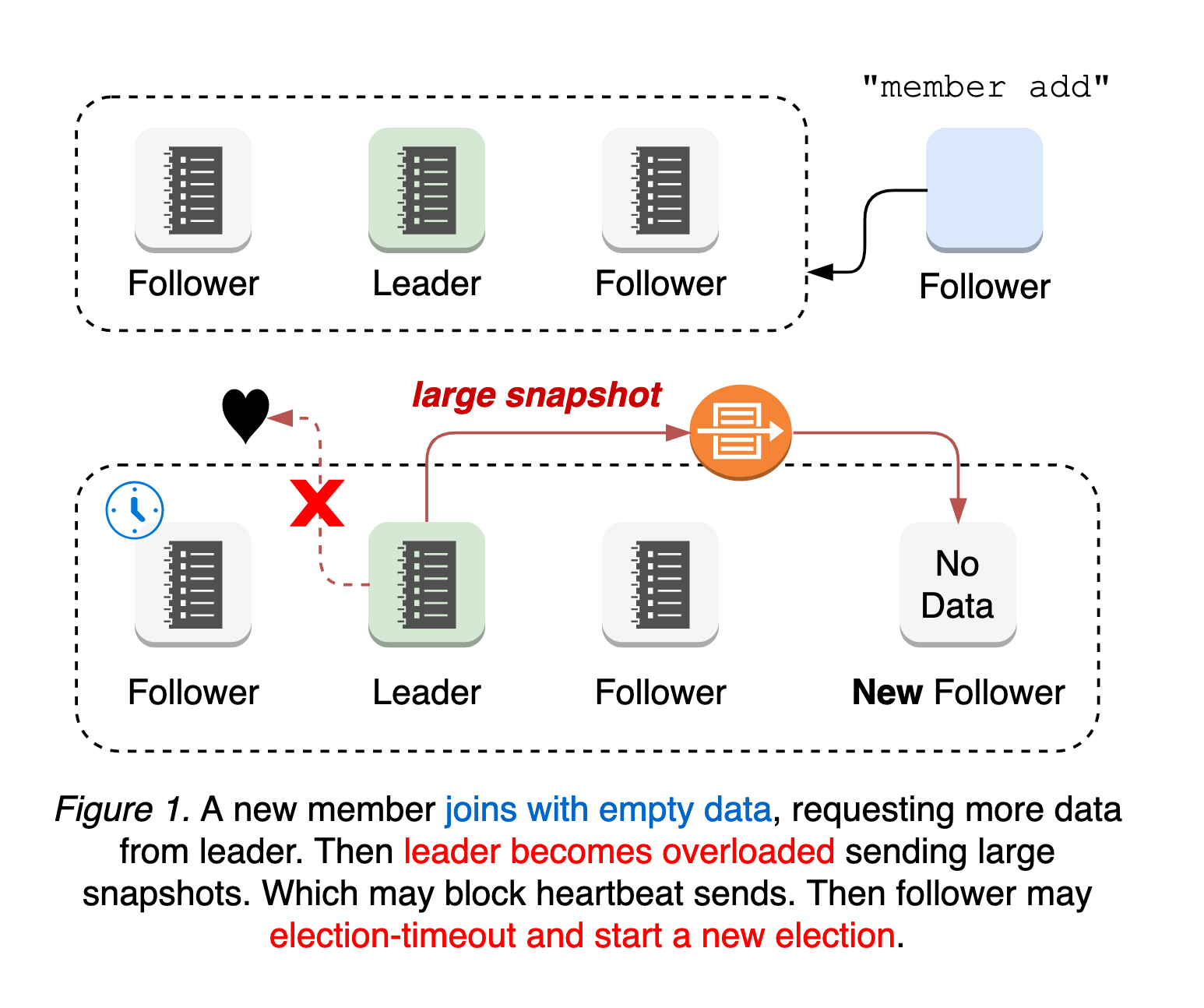
最糟糕的情况是成员添加的配置错误。etcd中的成员重新配置是一个两步过程:etcdctl member add peer的url,并启动一个新的etcd加入集群。也就是说,无论peer url值是否无效,都会执行member add命令。如果第一步是应用无效的url并更改仲裁大小,则在新节点连接之前,集群可能已经丢失仲裁。由于具有无效url的节点永远不可用,并且没有leader,因此也不可能恢复其成员资格的变化(参见图2)。
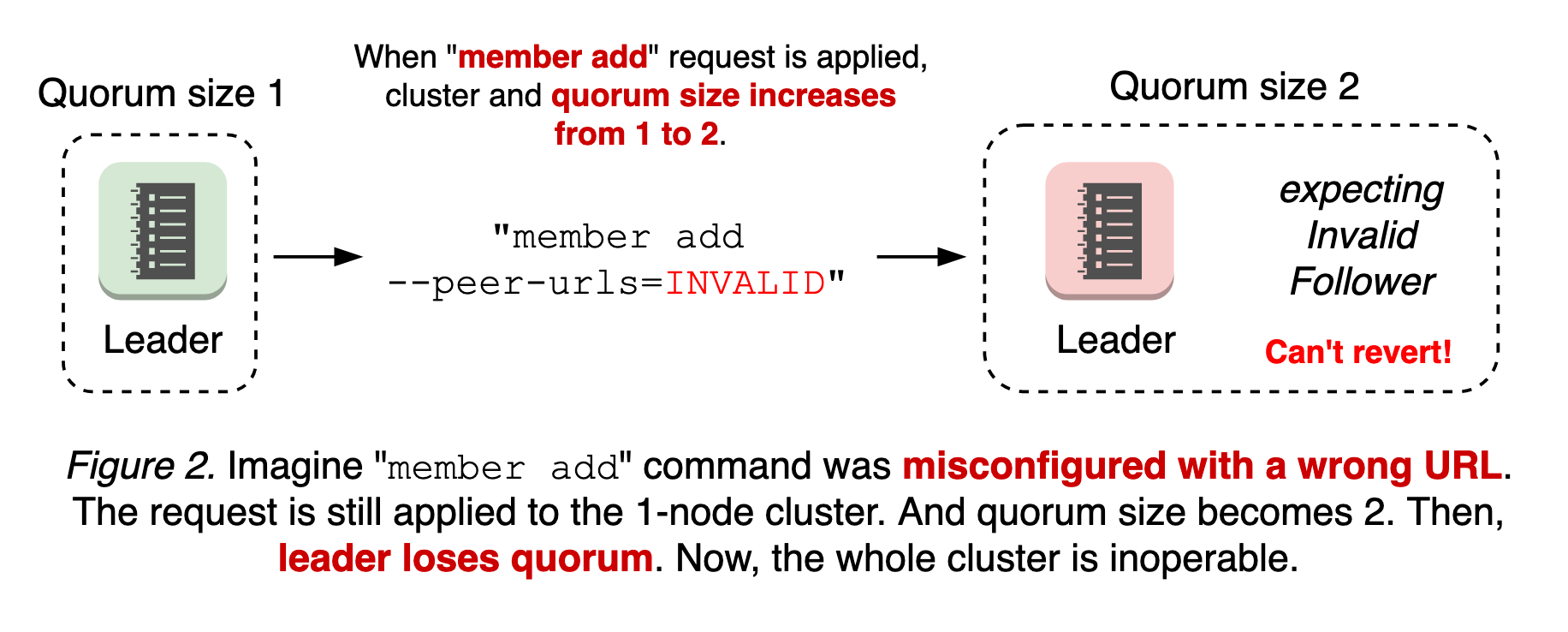
当存在分区节点时,这会变得更加复杂(有关更多信息,请参阅设计文档)。
为了解决这种故障情况,etcd引入了一个新的节点状态“Learner”,它作为无投票权成员加入集群,直到它赶上leader的日志。这意味着Learner(学习器)仍然接收来自leader的所有更新,而不计入leader用来评估活跃性的仲裁人数。learner在提升之前仅作为备用节点使用。这种对仲裁的宽松要求在成员重新配置和操作安全期间提供了更好的可用性(参见图3)。
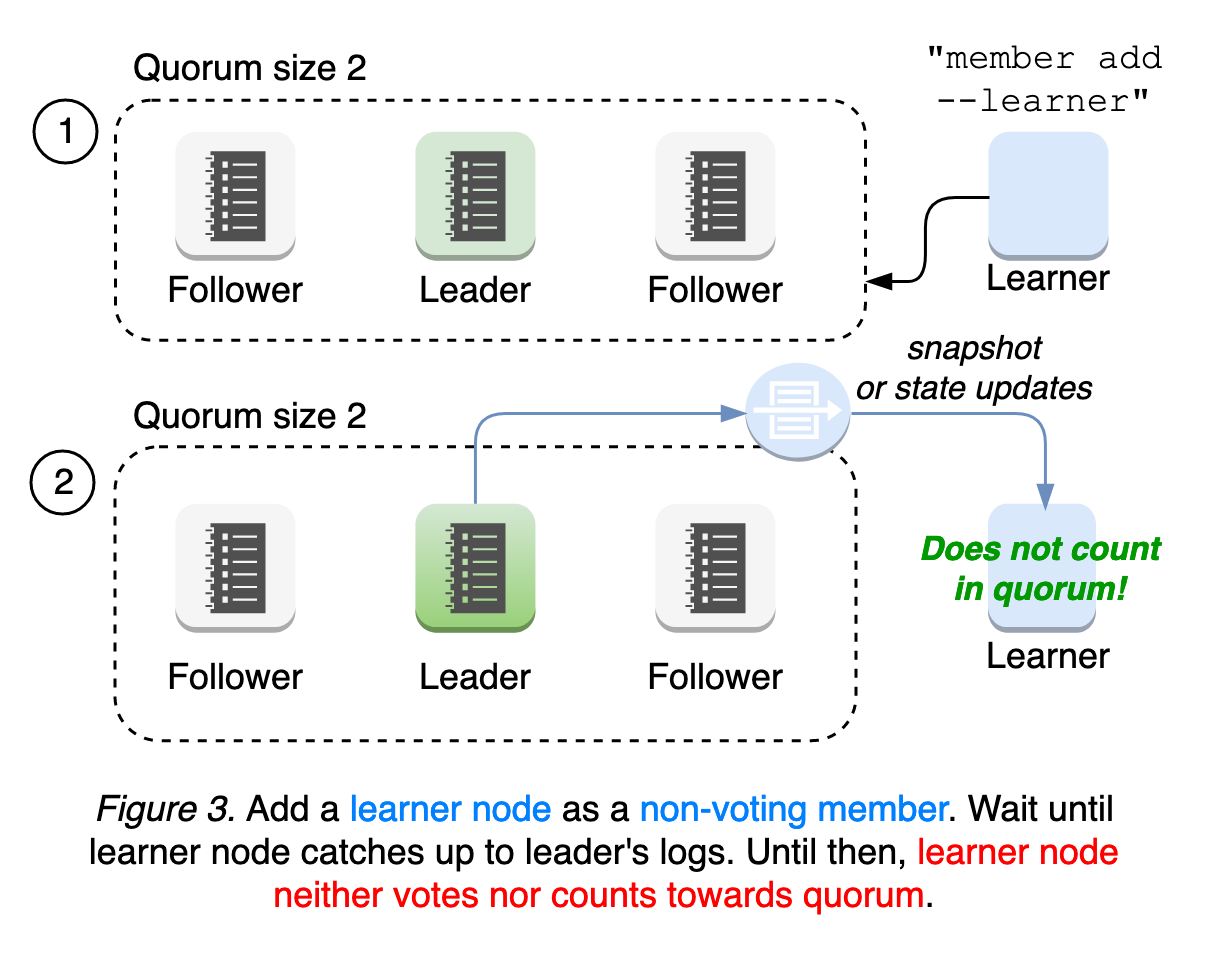
我们将进一步提高学习器的健壮性,并探索自动推动机制,以便更容易和更可靠。
新客户端平衡
ETCD容忍各种系统和网络故障。根据设计,即使一个节点出现故障,集群也会通过提供多个服务器的一个逻辑集群视图,使集群“看起来”正常工作。但是,这并不能保证客户端的正常。因此,etcd客户端实现了一组不同的复杂协议,以保证其在故障情况下的正确性和高可用性。
过去,etcd客户端平衡严重依赖于旧的grpc接口:每次grpc依赖升级都会破坏客户端行为。大多数开发和调试工作都致力于修复这些客户端行为。因此,由于对服务器连接性的错误假设,它的实现变得过于复杂。etcd v3.4客户端主要目标是简化中的平衡故障转移逻辑;只要客户端与当前端点断开连接时,就可以简单的循环到下一个端点,无需假定端点的状态。而不是向之前维护一个不健康的端点列表(这个列表可能已经无效了)。
另外,新客户端现在创建了自己的凭证包来修复针对安全端点的平衡故障转移。这解决了长达一年的bug(当第一台etcd服务器不可用时,kube apiserver将失去与etcd集群的连接)。
相关推荐
有关更改的完整列表,请参阅CHANGELOG。


